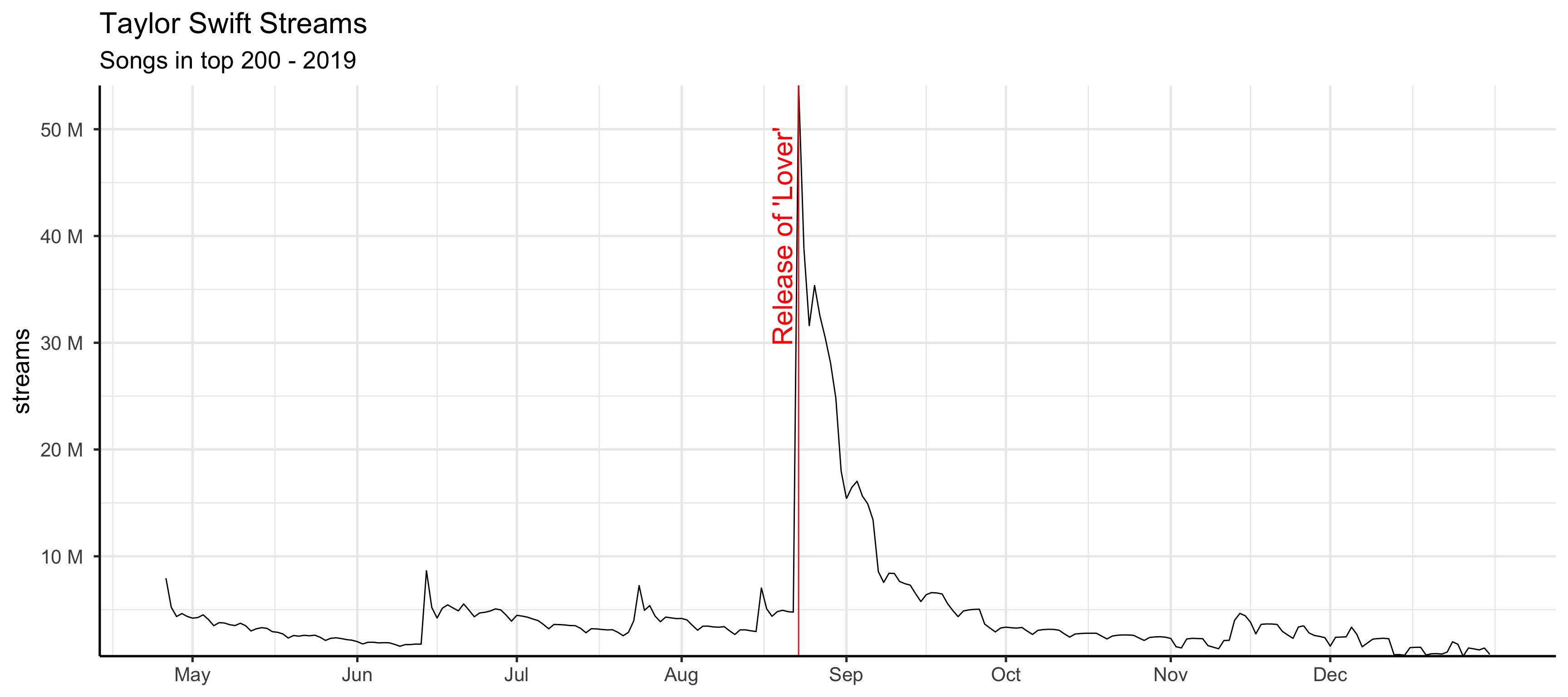
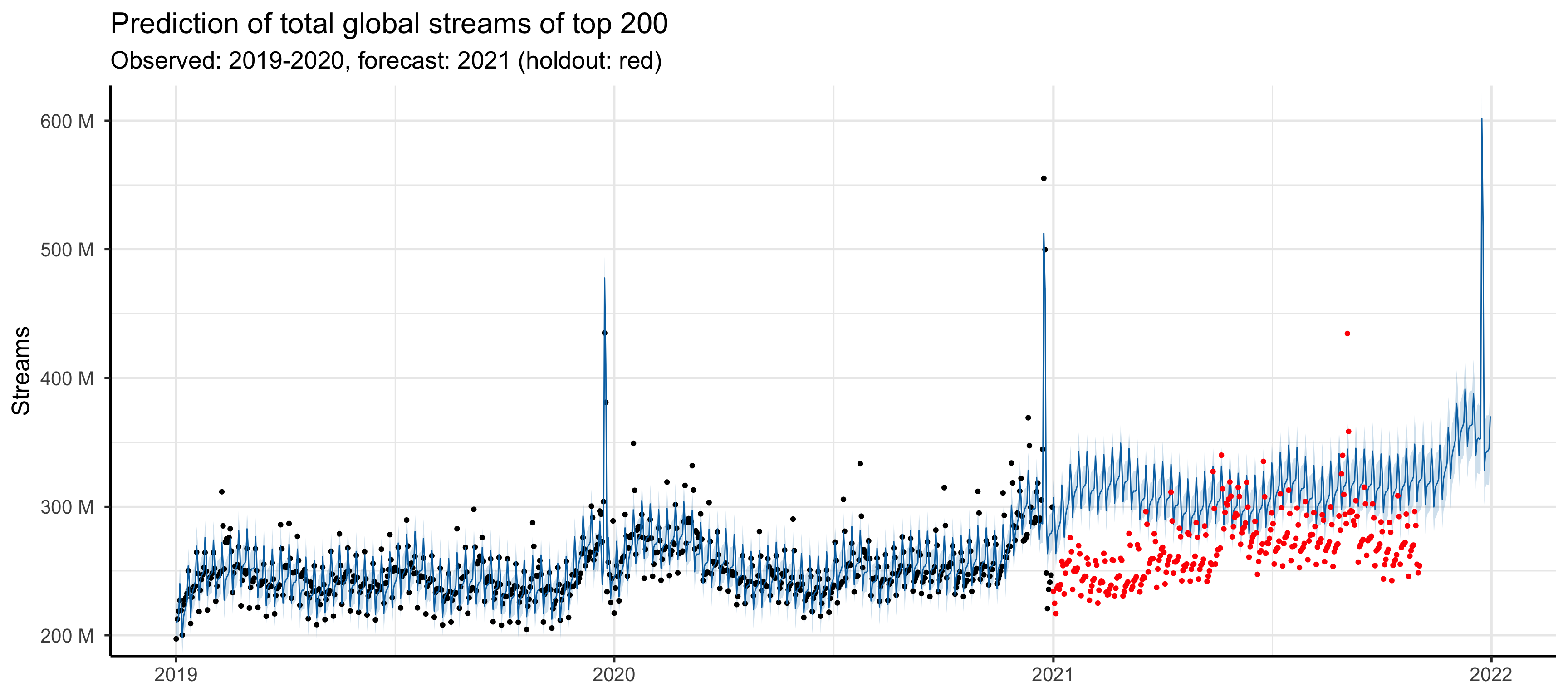
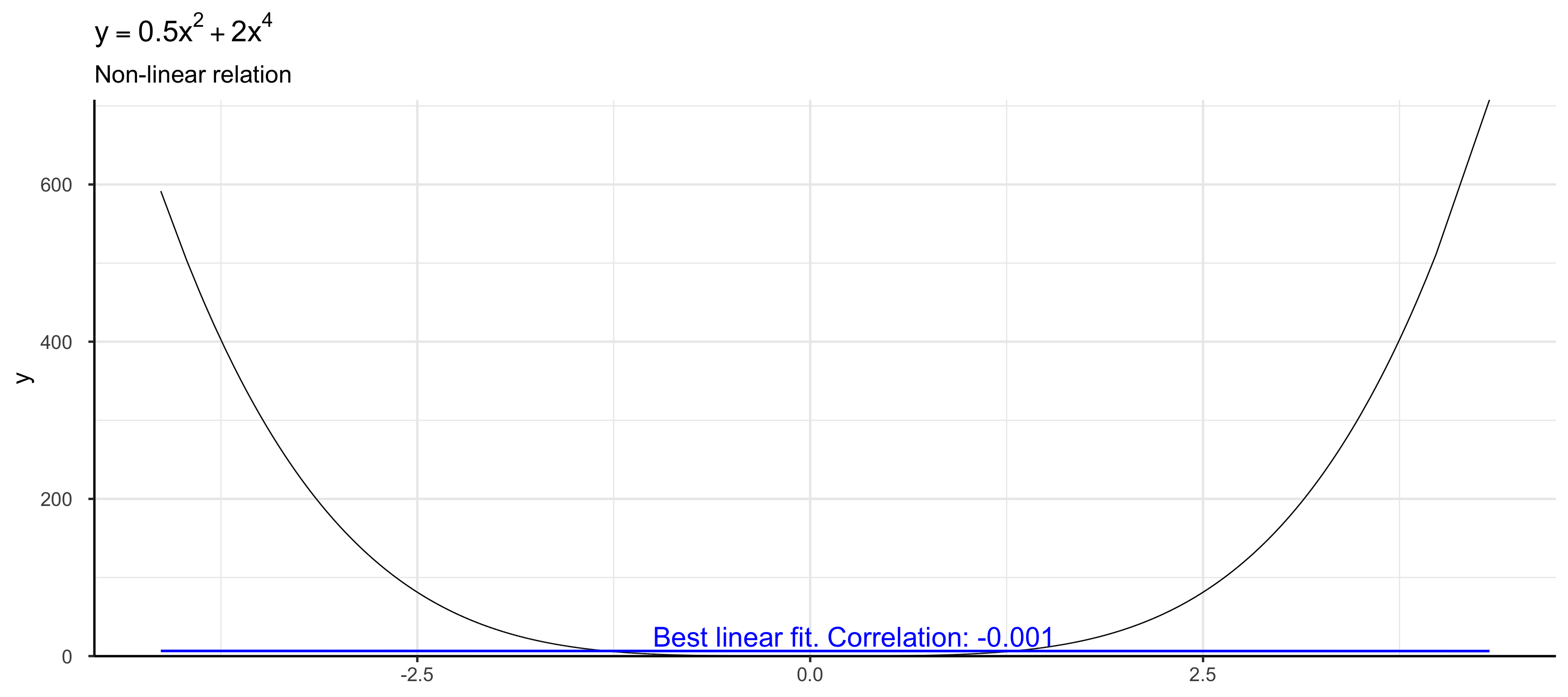
Aguiar, Luis, and Joel Waldfogel. 2016.
“Quality Predictability and the Welfare Benefits from New Products: Evidence from the Digitization of Recorded Music.” Working Paper. Working
Paper Series.
National Bureau of Economic Research.
https://doi.org/10.3386/w22675.
Berger, Jonah A., Wendy W. Moe, and David A. Schweidel. 2022.
“What Holds Attention? Linguistic Drivers of Engagement.” SSRN Scholarly Paper.
Rochester, NY.
https://doi.org/10.2139/ssrn.4311202.
Berger, Jonah, and Katherine L. Milkman. 2012.
“What Makes Online Content Viral?” Journal of Marketing Research 49 (2): 192–205.
https://doi.org/10.1509/jmr.10.0353.
Boughanmi, Khaled, and Asim Ansari. 2021.
“Dynamics of Musical Success: A Machine Learning Approach for Multimedia Data Fusion.” Journal of Marketing Research, April, 00222437211016495.
https://doi.org/10.1177/00222437211016495.
Callaway, Brantly, and Pedro H. C. Sant’Anna. 2021.
“Difference-in-Differences with Multiple Time Periods.” Journal of Econometrics, Themed issue: Treatment effect 1, 225 (2): 200–230.
https://doi.org/10.1016/j.jeconom.2020.12.001.
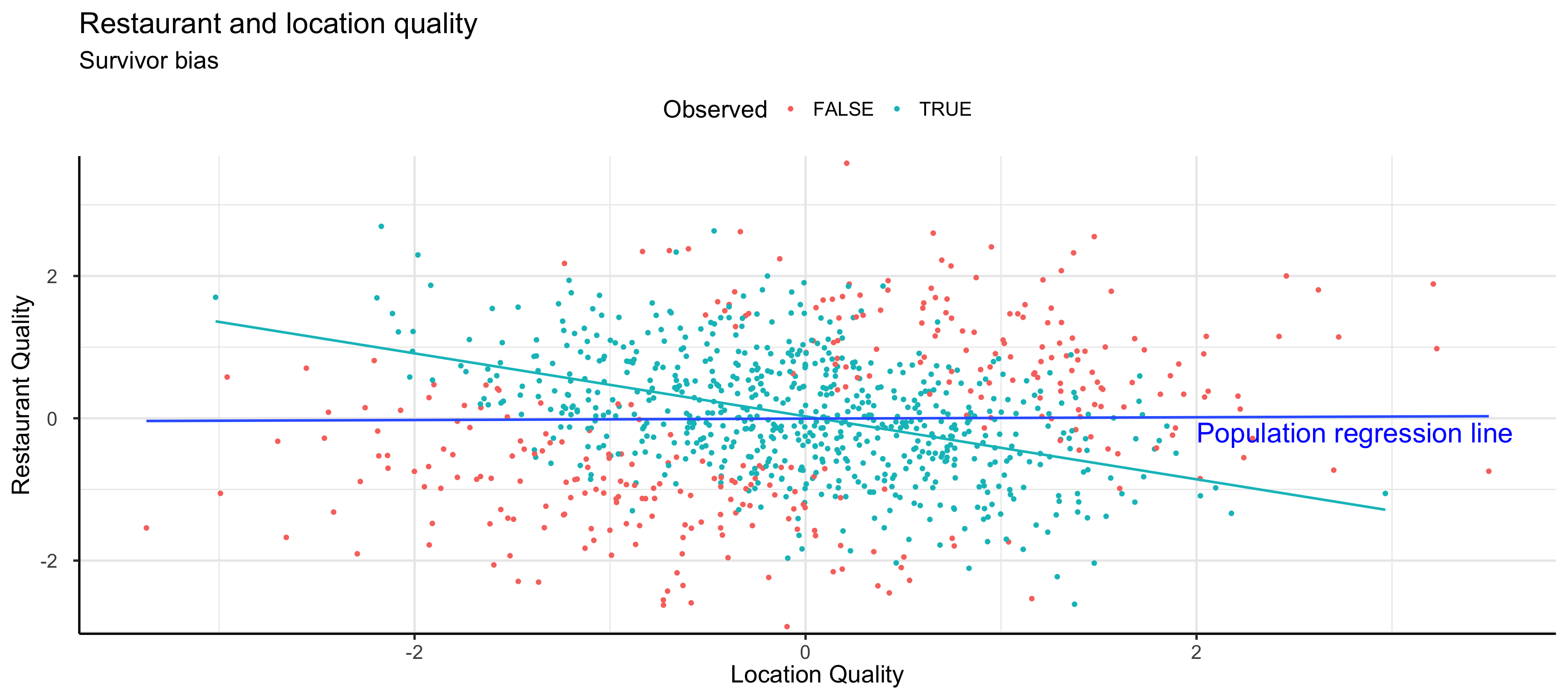
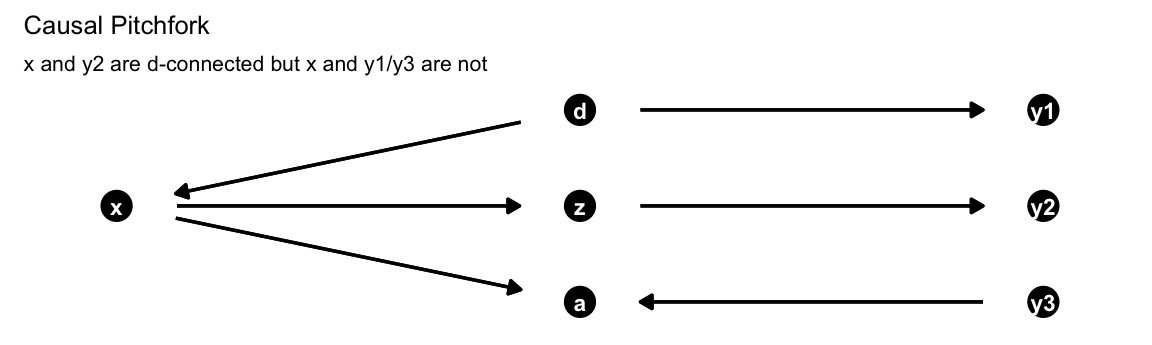
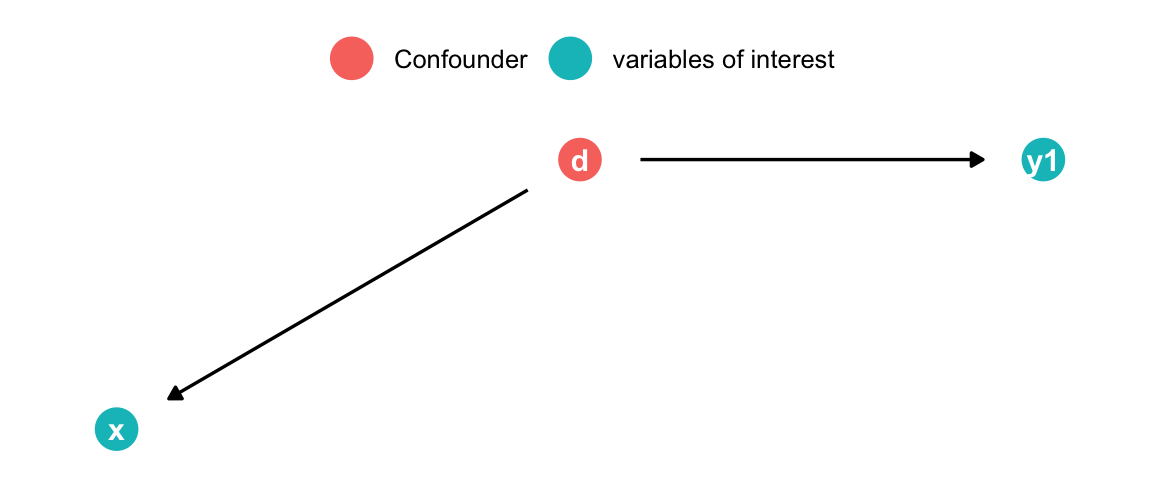
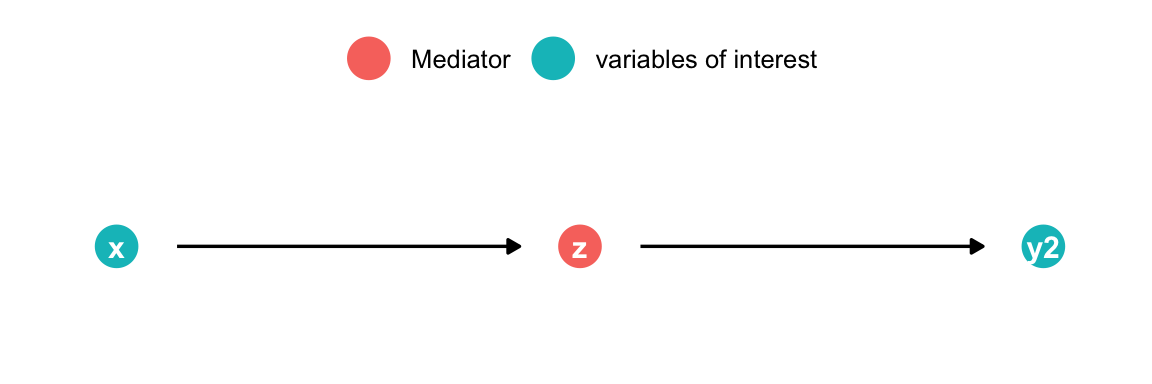
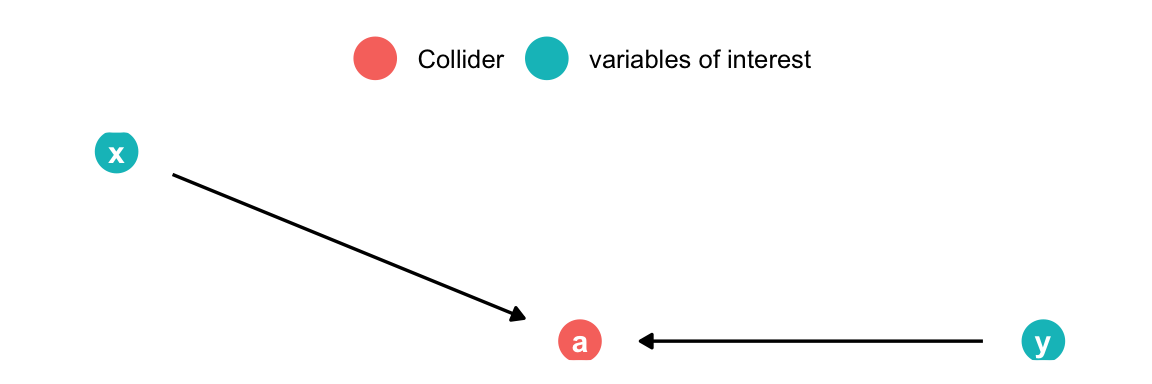
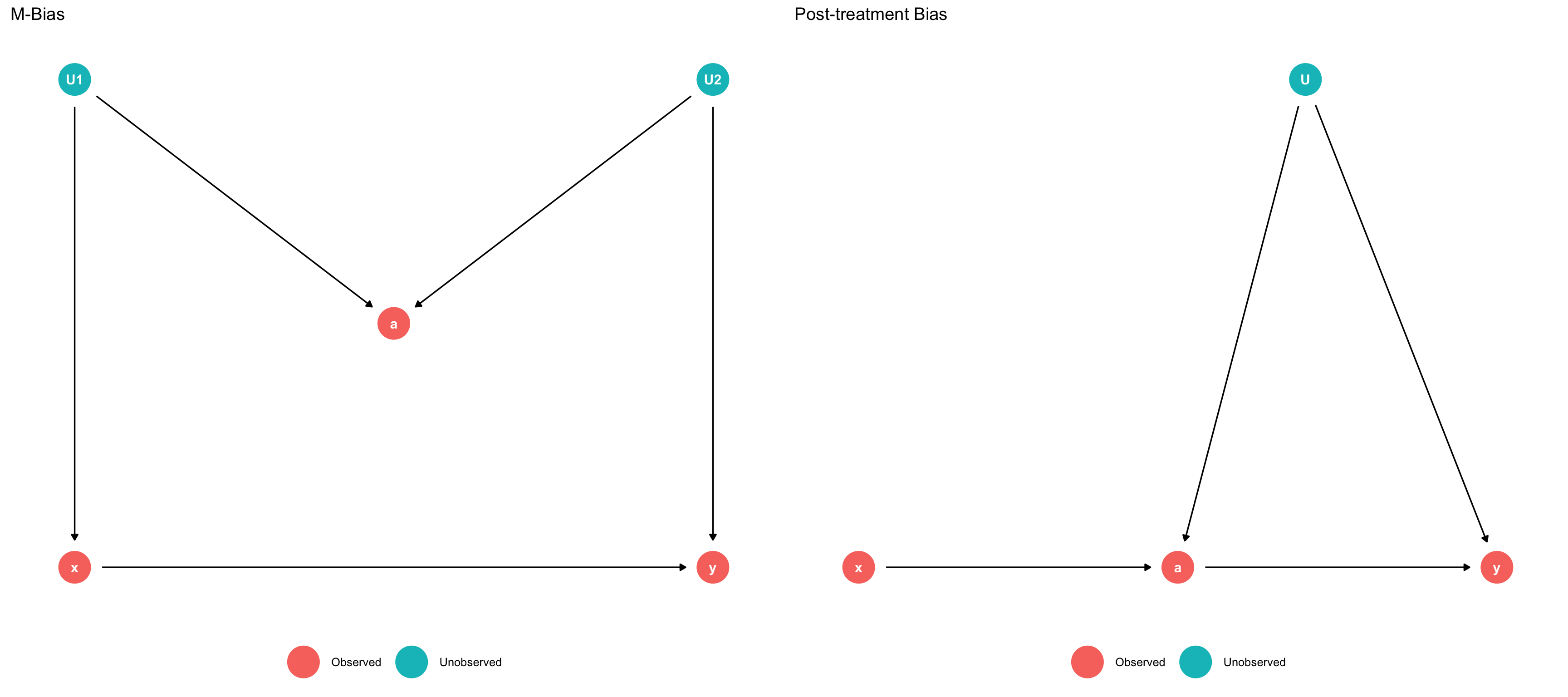
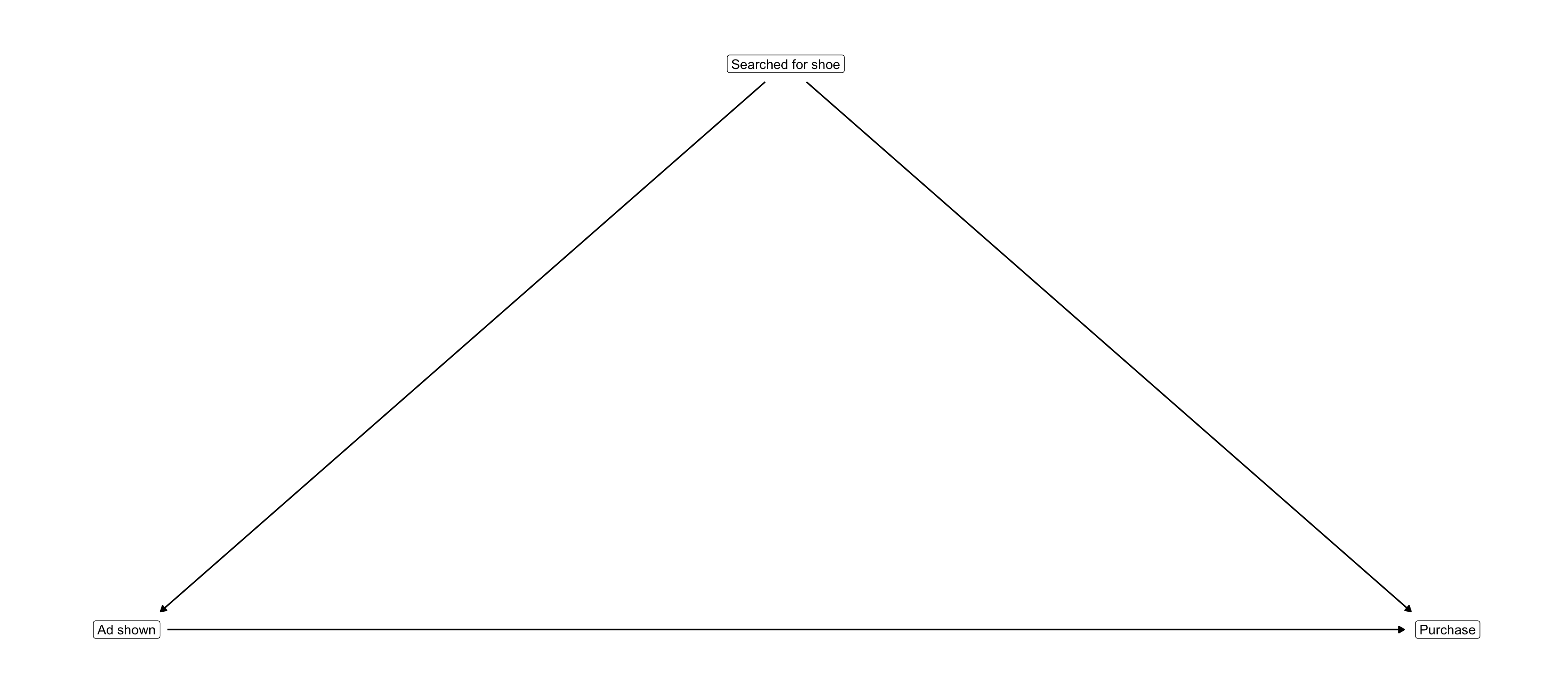
Cinelli, Carlos, Andrew Forney, and Judea Pearl. 2020. “A Crash Course in Good and Bad Controls.” SSRN 3689437.
Filippas, Apostolos, John J. Horton, and Joseph M. Golden. 2022.
“Reputation Inflation.” Marketing Science 41 (4): 733–45.
https://doi.org/10.1287/mksc.2022.1350.
Imbens, Guido W. 2020.
“Potential Outcome and Directed Acyclic Graph Approaches to Causality: Relevance for Empirical Practice in Economics.” Journal of Economic Literature 58 (4): 1129–79.
https://doi.org/10.1257/jel.20191597.
Kim, Aekyoung, Felipe M. Affonso, Juliano Laran, and Kristina M. Durante. 2021.
“Serendipity: Chance Encounters in the Marketplace Enhance Consumer Satisfaction.” Journal of Marketing 85 (4): 141–57.
https://doi.org/10.1177/00222429211000344.
Ordanini, Andrea, and Joseph C. Nunes. 2016.
“From Fewer Blockbusters by More Superstars to More Blockbusters by Fewer Superstars: How Technological Innovation Has Impacted Convergence on the Music Chart.” International Journal of Research in Marketing, The
Entertainment Industry, 33 (2): 297–313.
https://doi.org/10.1016/j.ijresmar.2015.07.006.
Pachali, Max J., and Hannes Datta. 2022. “What Drives Demand for Playlists on Spotify?” Available at SSRN.
Rocklage, Matthew D., Derek D. Rucker, and Loran F. Nordgren. 2021.
“Mass-Scale Emotionality Reveals Human Behaviour and Marketplace Success.” Nature Human Behaviour 5 (10): 1323–29.
https://doi.org/10.1038/s41562-021-01098-5.
Wlömert, Nils, and Dominik Papies. 2019.
“International Heterogeneity in the Associations of New Business Models and Broadband Internet with Music Revenue and Piracy.” International Journal of Research in Marketing, Marketing
Perspectives on
Digital Business Models, 36 (3): 400–419.
https://doi.org/10.1016/j.ijresmar.2019.01.007.