causal model typically worse in terms of prediction
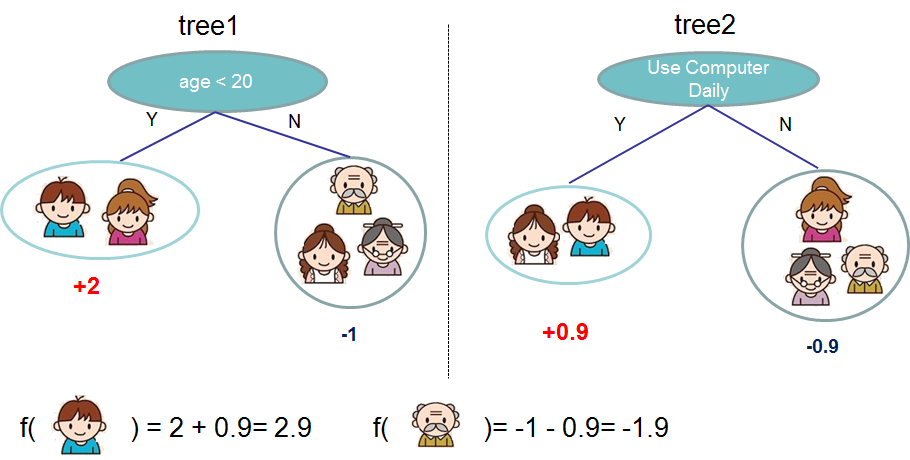
Allows flexible model structure
Goal: extrapolate well (small error) to unknown outcome given new observed input
Definition of “error” (loss) depends on the outcome variable and problem (e.g., binary \(\rightarrow\) sensitivity/specificity, continuous \(\rightarrow\) squared/absolute error)
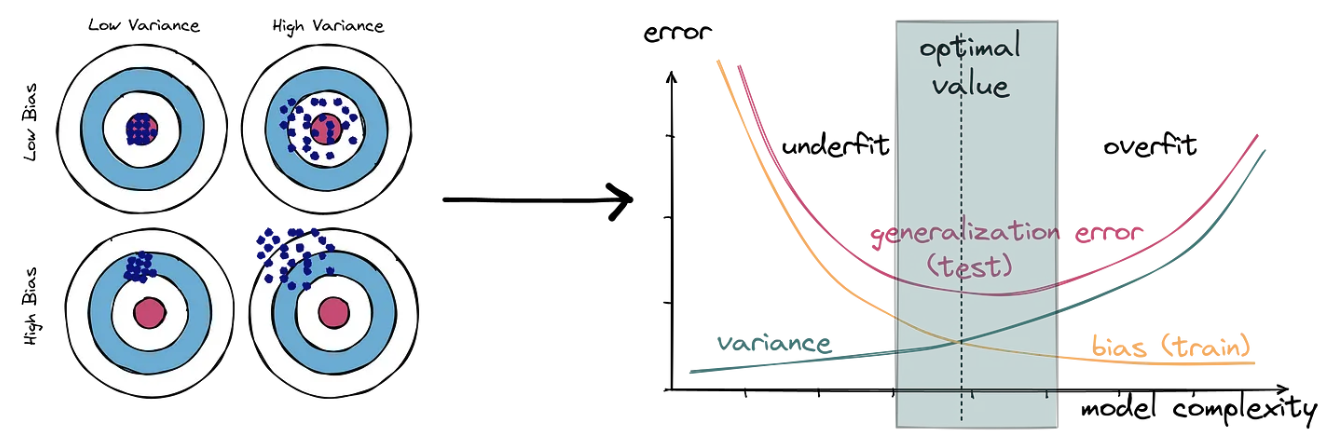
Fundamental issue: overfitting
Each observed outcome contains signal and noise
signal: part that is associated with inputs
noise: additional variation e.g., measurement error, unobserved factors, random nature of outcome
will be different in new data
overfitting: in addition to the signal the model also picks up on the noise of the data used to “fit” (train) the parameters
library(modelsummary)library(Metrics)set.seed(42)x <-runif(1000, -100, 100)y <-12.5+7* x +rnorm(length(x), mean =0, sd =1000 )model_data <-data.frame(x,y)mod.ols <-lm(y~x, data = model_data)modelsummary(list(OLS = mod.ols), output="markdown")
OLS
(Intercept)
-17.447
(31.640)
x
7.676
(0.543)
Num.Obs.
1000
R2
0.167
R2 Adj.
0.166
AIC
16656.8
BIC
16671.6
Log.Lik.
-8325.414
F
200.071
RMSE
998.72
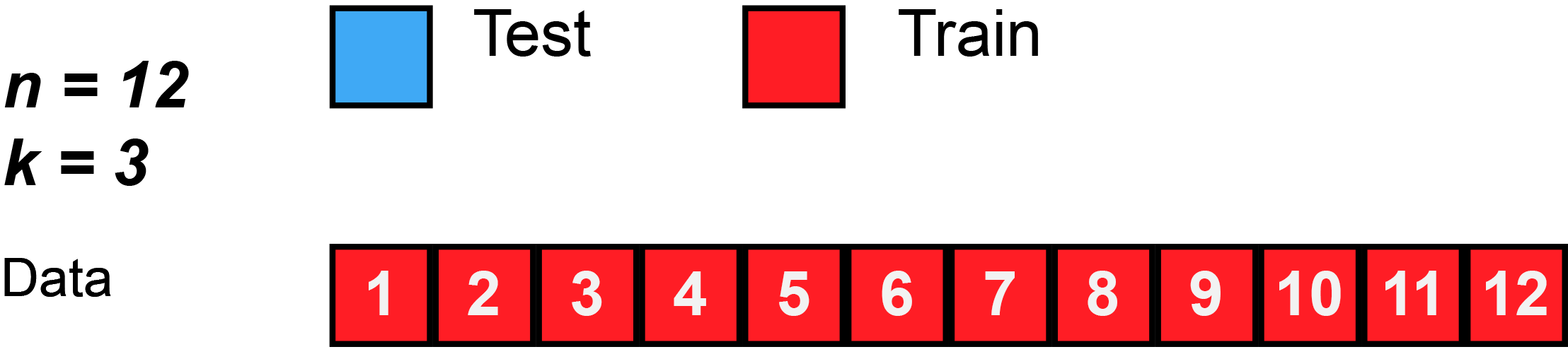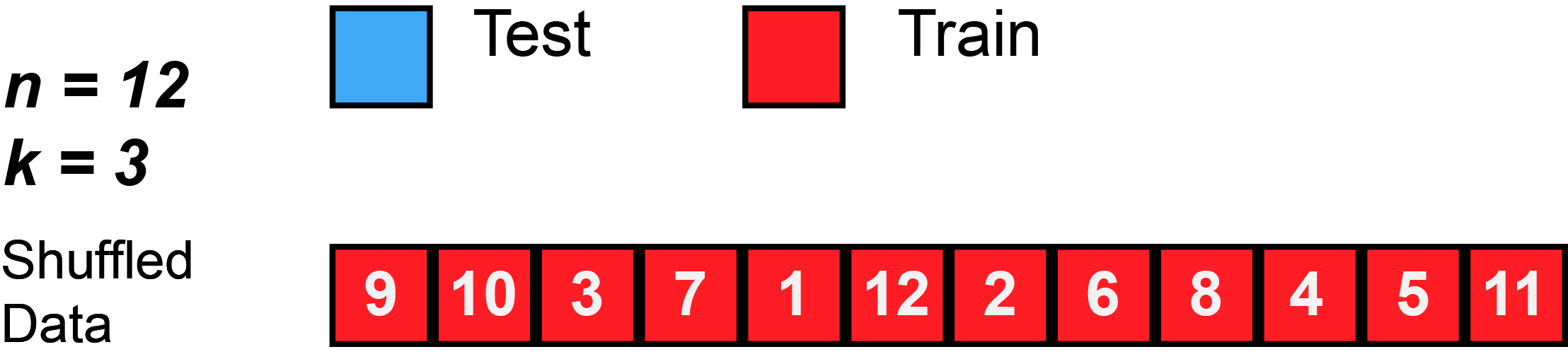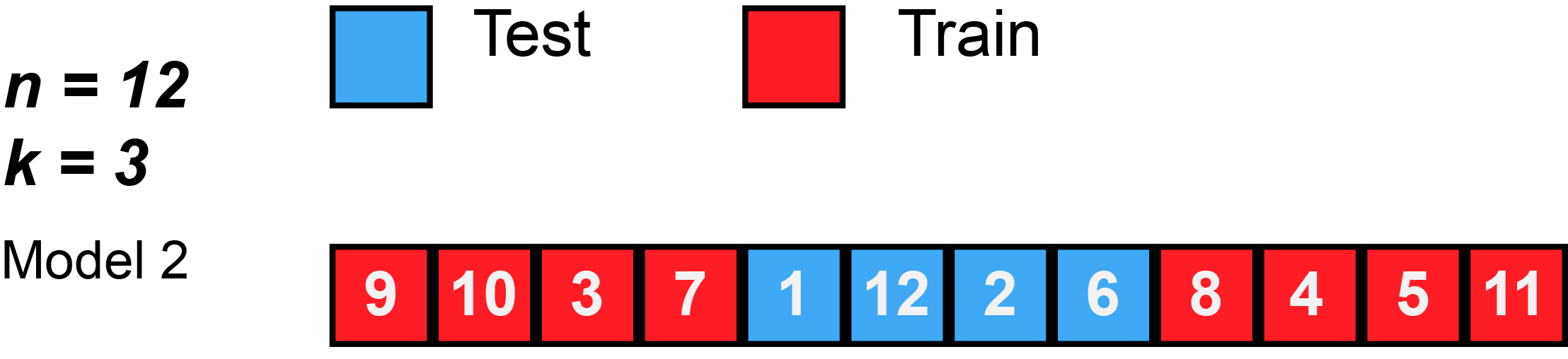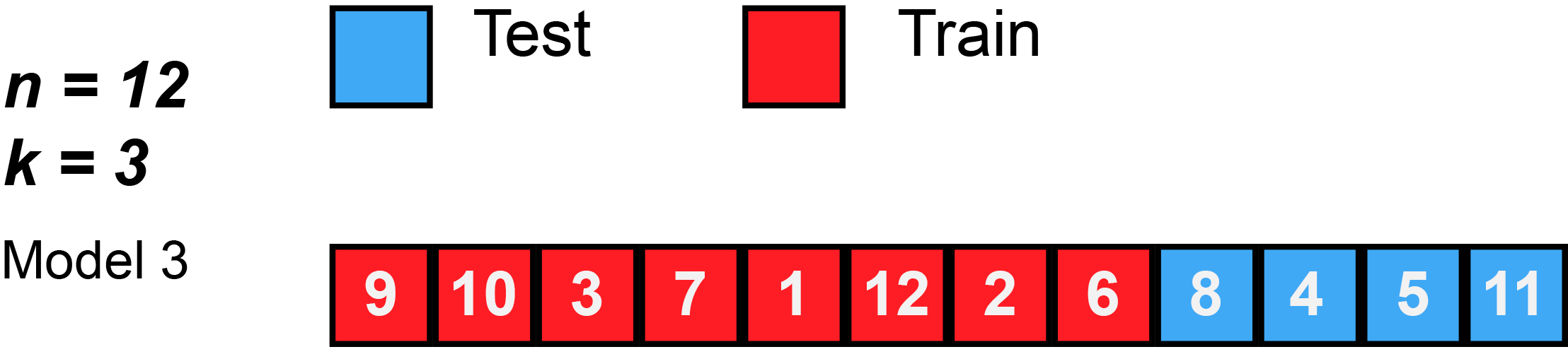
Check for overfitting: data prep
Train/Test split
Use e.g., 80% of the sample to fit the model and 20% to test its performance on new data
In real life: do this many times with different splits to see patterns
library(rsample)split_xy <-initial_split(model_data, prop =0.8)training_xy <-training(split_xy)testing_xy <-testing(split_xy)print("Signal vs. Noise")
[1] "Signal vs. Noise"
summary(training_xy)
x y
Min. :-99.919 Min. :-3495.10
1st Qu.:-53.554 1st Qu.: -786.51
Median : -3.720 Median : -60.38
Mean : -1.075 Mean : -49.86
3rd Qu.: 51.472 3rd Qu.: 722.85
Max. : 99.698 Max. : 3155.77
summary(testing_xy)
x y
Min. :-99.952 Min. :-3410.78
1st Qu.:-55.411 1st Qu.: -546.54
Median : -5.878 Median : 58.90
Mean : -7.446 Mean : 22.05
3rd Qu.: 42.628 3rd Qu.: 702.45
Max. : 98.159 Max. : 3910.81
Check for overfitting
Check for differences in model performance in the training and test samples
RMSE: Root Mean Squared Error \(\sqrt{\frac{1}{n}\sum_{i=1}^n (y - \hat y)^2}\)
mod.ols.train <-lm(y ~ x, data = training_xy)modelsummary(mod.ols.train, gof_omit ="R2|IC|Log|F")
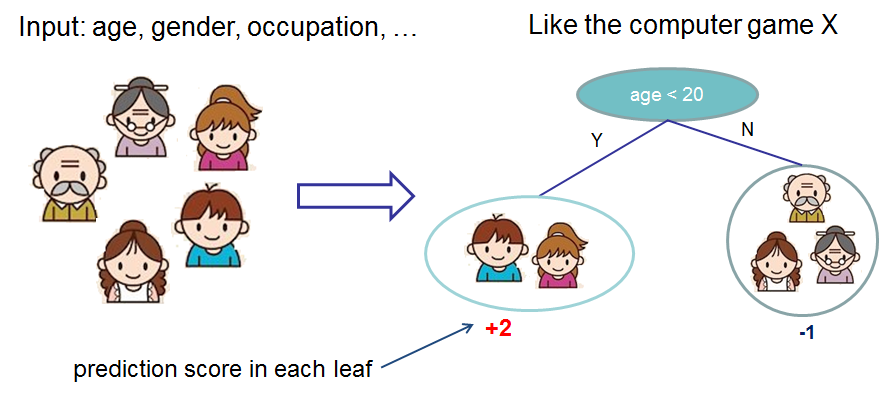
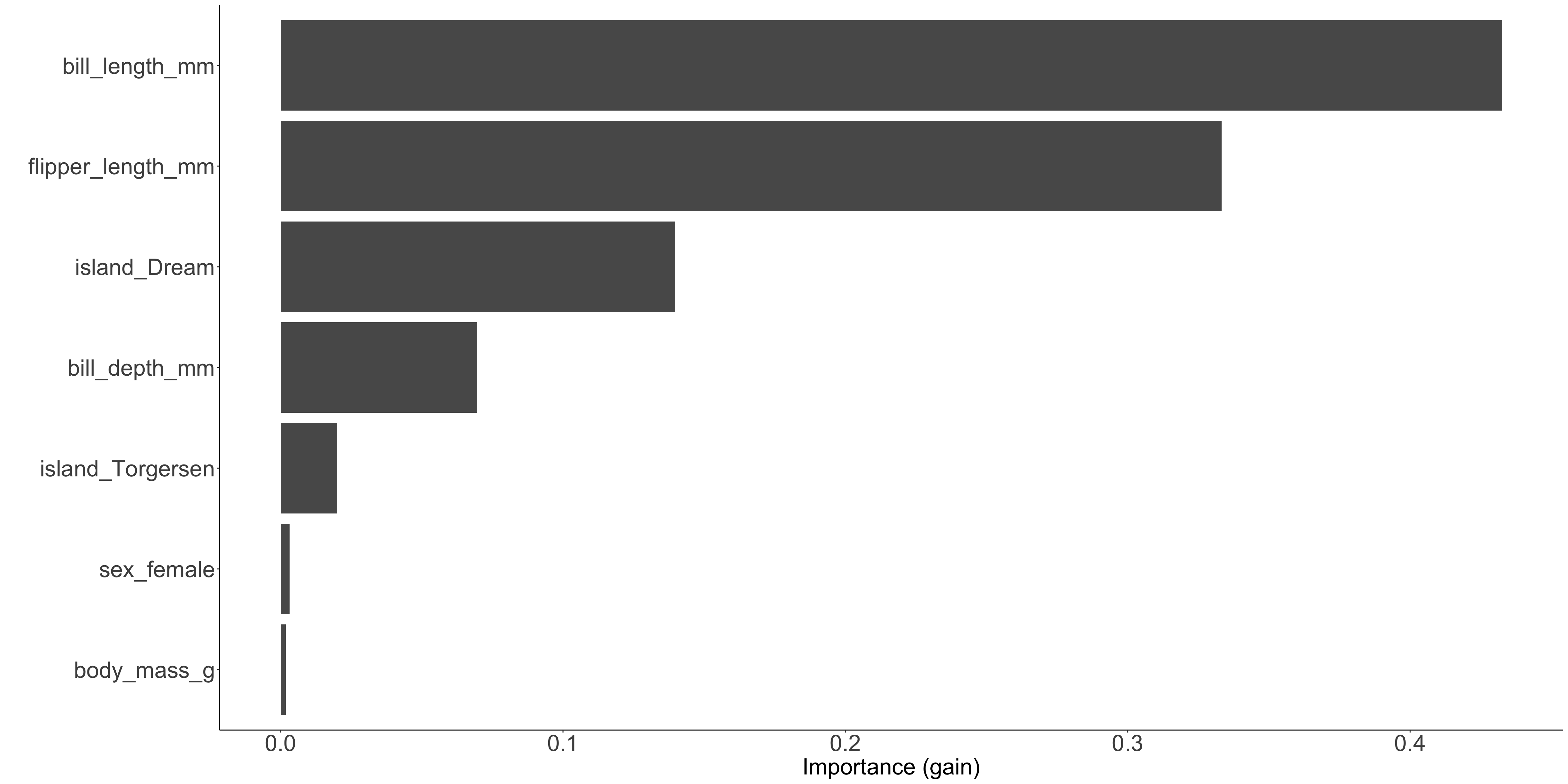
Predict the penguin species based on the observed data
Numeric features can be used as they are
Categorical features have to be encoded into numeric features
most common: one-hot encoding (indicator function)
in this case: island, sex
penguins <-drop_na(penguins)penguin_dummies <-recipe(species ~ ., penguins) |>step_dummy(all_nominal_predictors(), one_hot =TRUE)# see ?step_dummy for other encoding optionshead(penguins)
## Select best learning ratebest_lr <- lr_tuning |>select_best()## Set best learning rate for the modelspecies_pred_wf_best1 <- species_pred_wf |>finalize_workflow(best_lr)species_pred_wf_best1
══ Workflow ════════════════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: boost_tree()
── Preprocessor ────────────────────────────────────────────────────────────────
1 Recipe Step
• step_dummy()
── Model ───────────────────────────────────────────────────────────────────────
Boosted Tree Model Specification (classification)
Main Arguments:
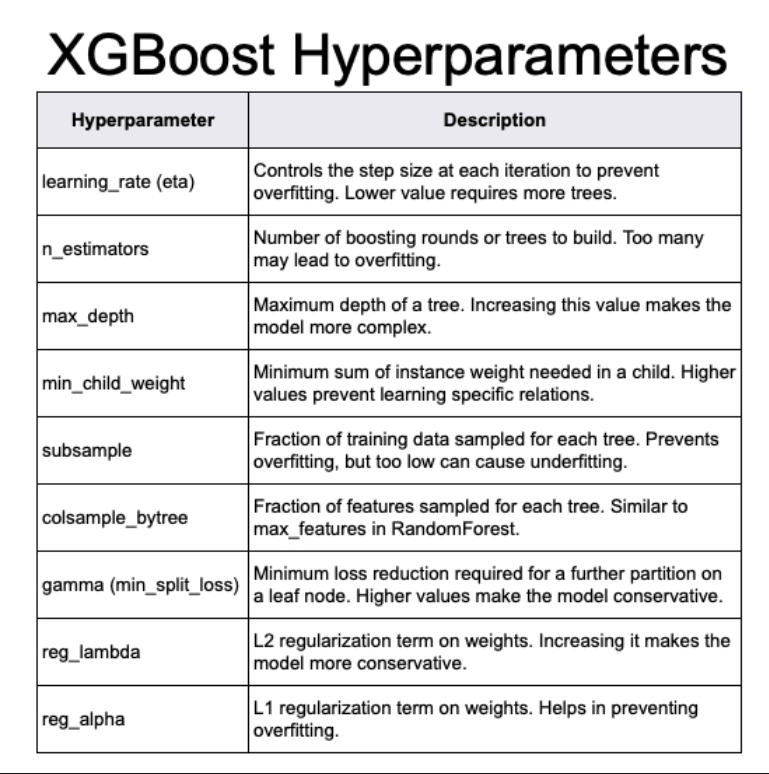
learn_rate = 0.186431577754487
Computational engine: xgboost
Fit the final model
Fit the model and add predictions to the original data
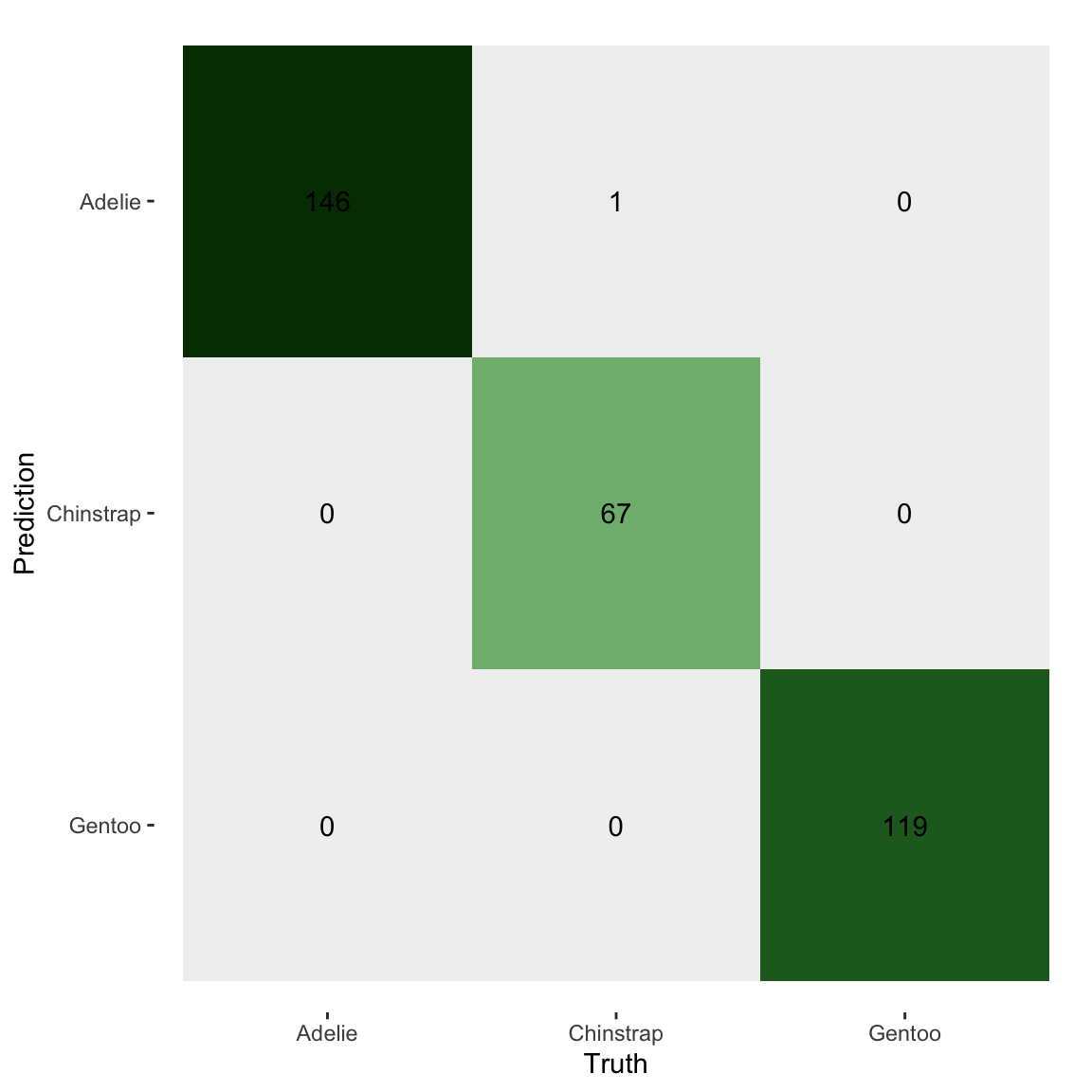
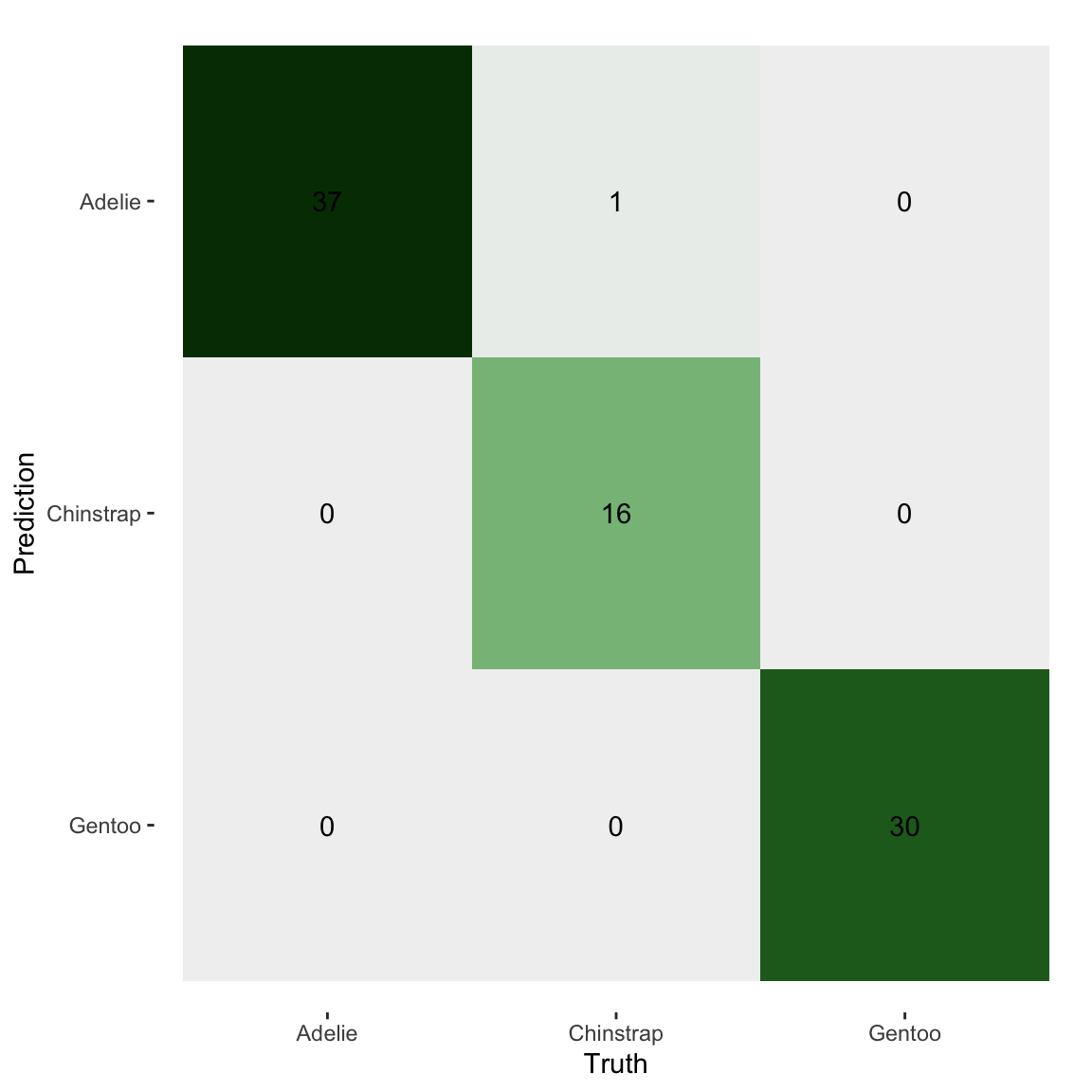
Plot the confusion matrix (true vs. predicted class counts)
{kind=link}