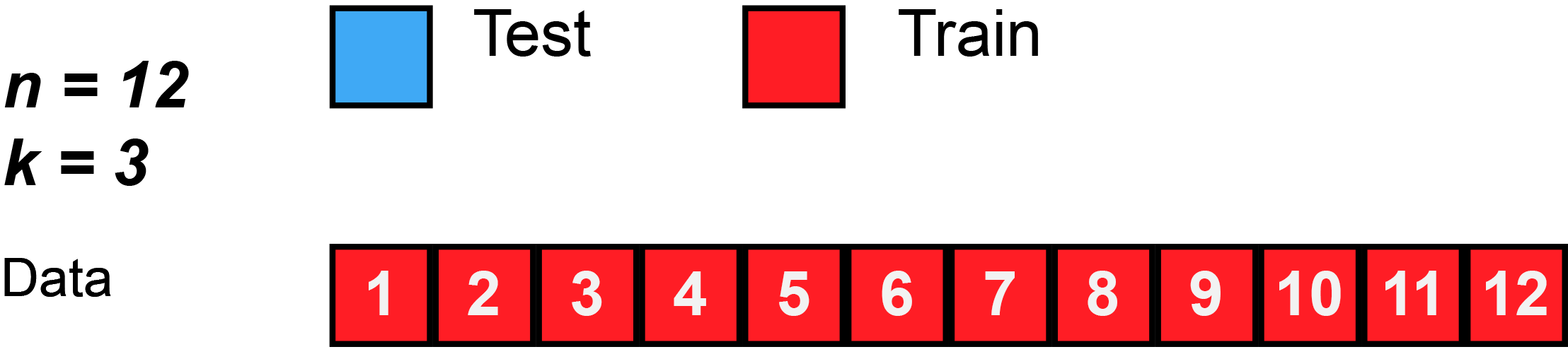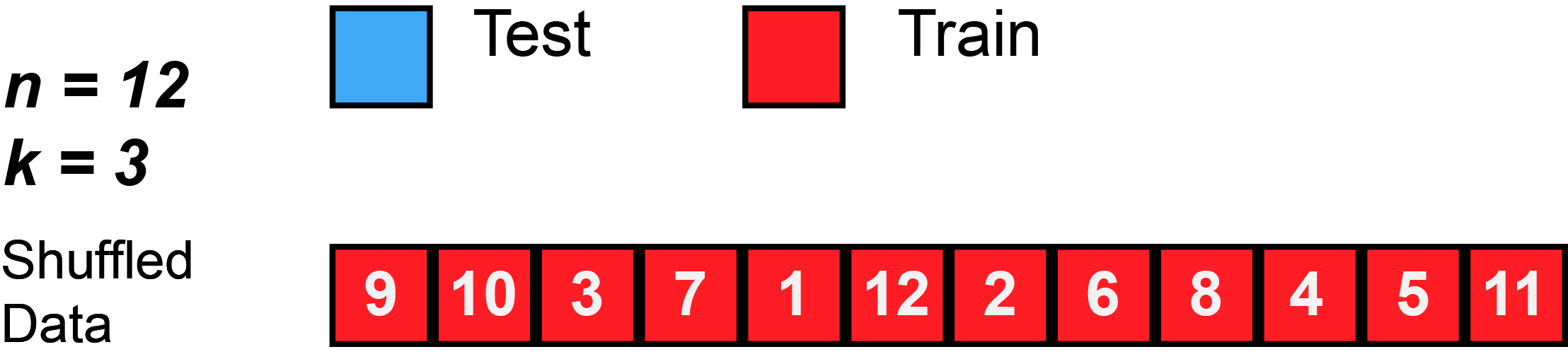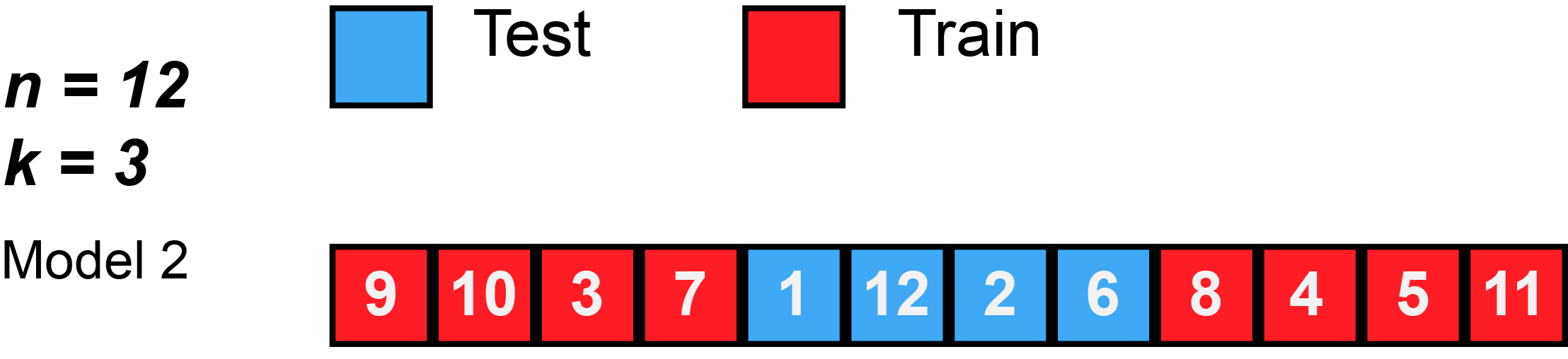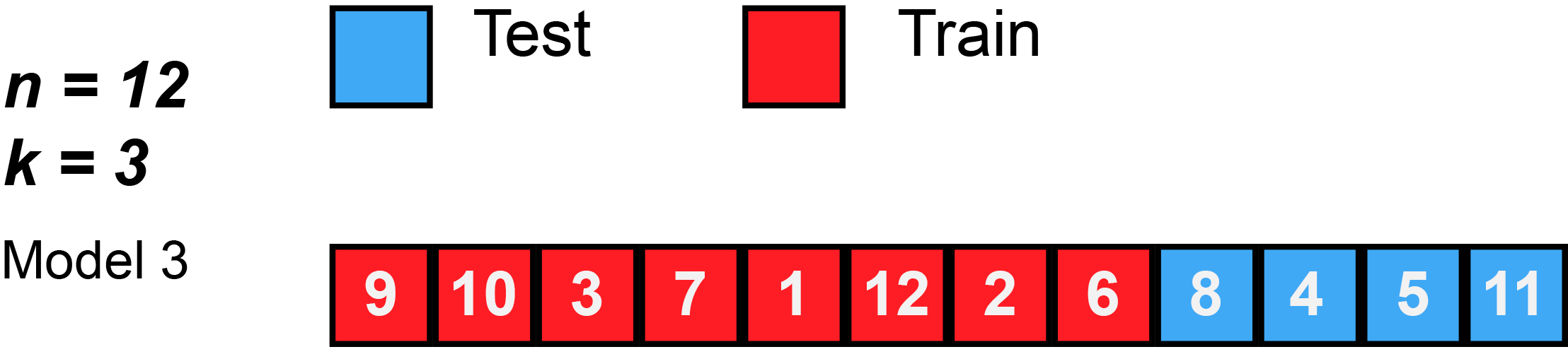
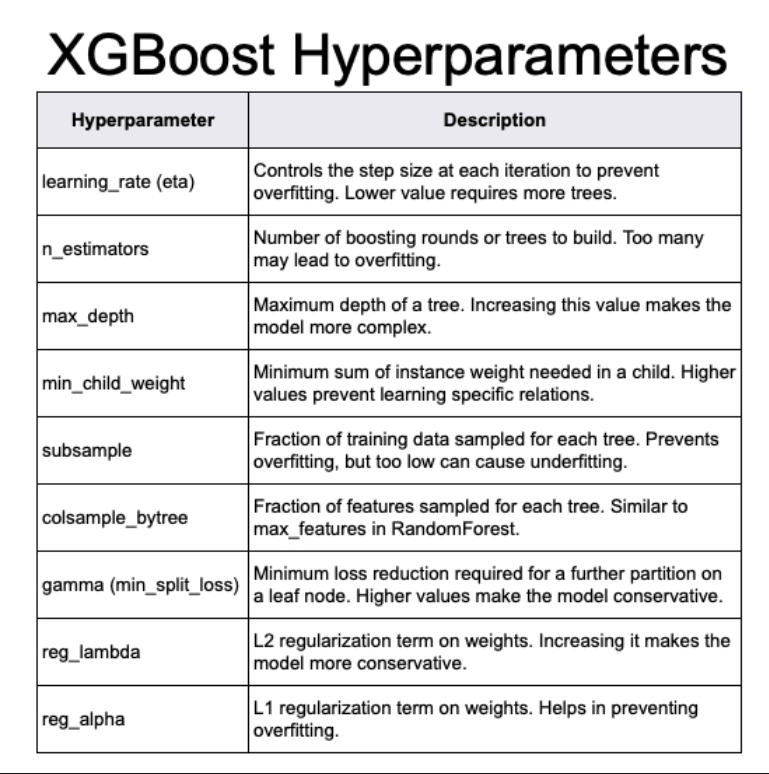
mod.powers.train <- lm(y ~ poly(x, degrees = 25), data = training_xy)
Metrics::rmse(training_xy$y, predict(mod.powers.train))[1] 987.8615[1] 1002.229XGBoost
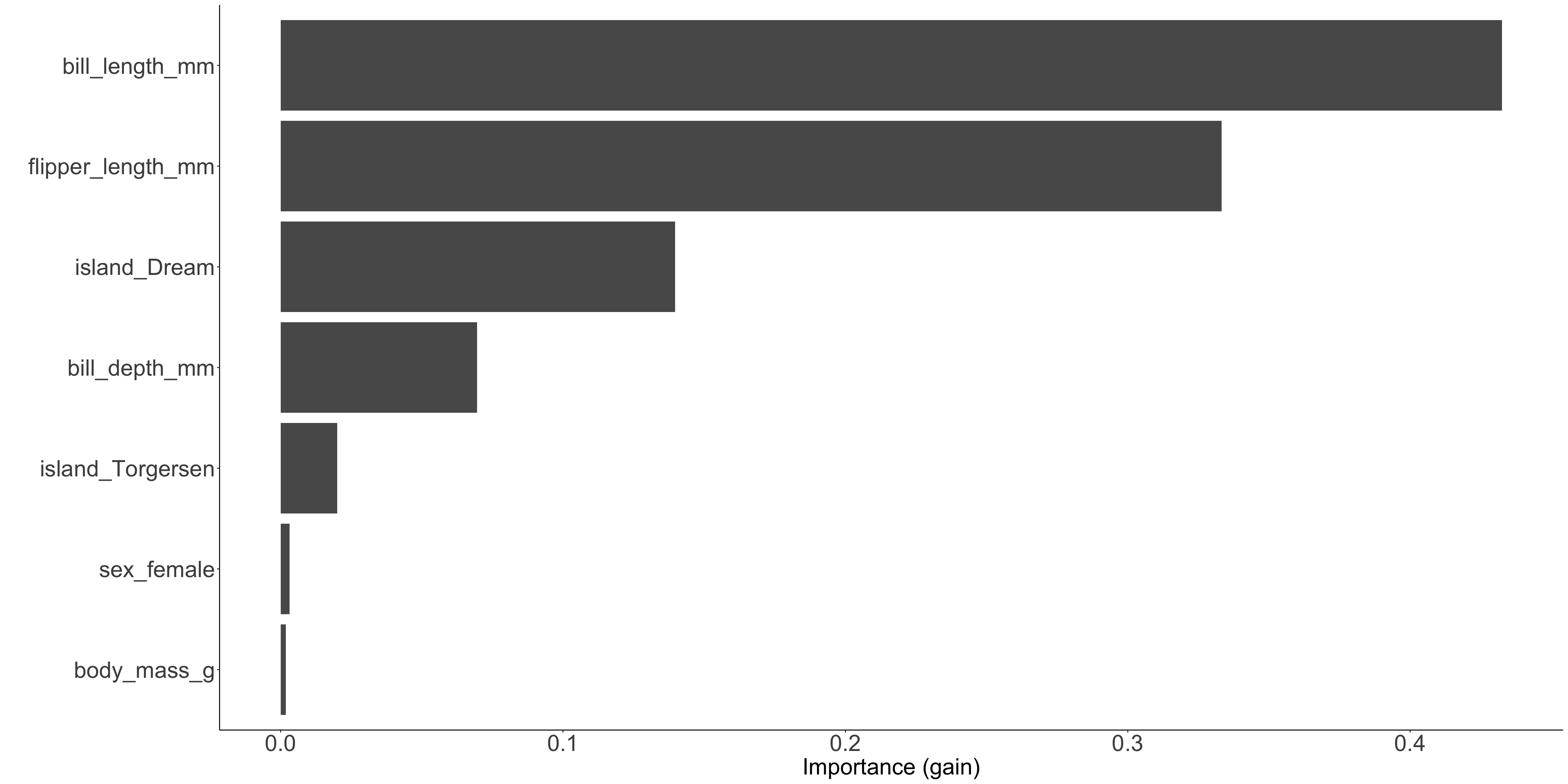
library(colorspace)
set.seed(1)
penguin_fit <- species_pred_wf_best1 |>
fit(penguins)
penguins$pred <- penguin_fit |>
predict(penguins) |>
pull(.pred_class)
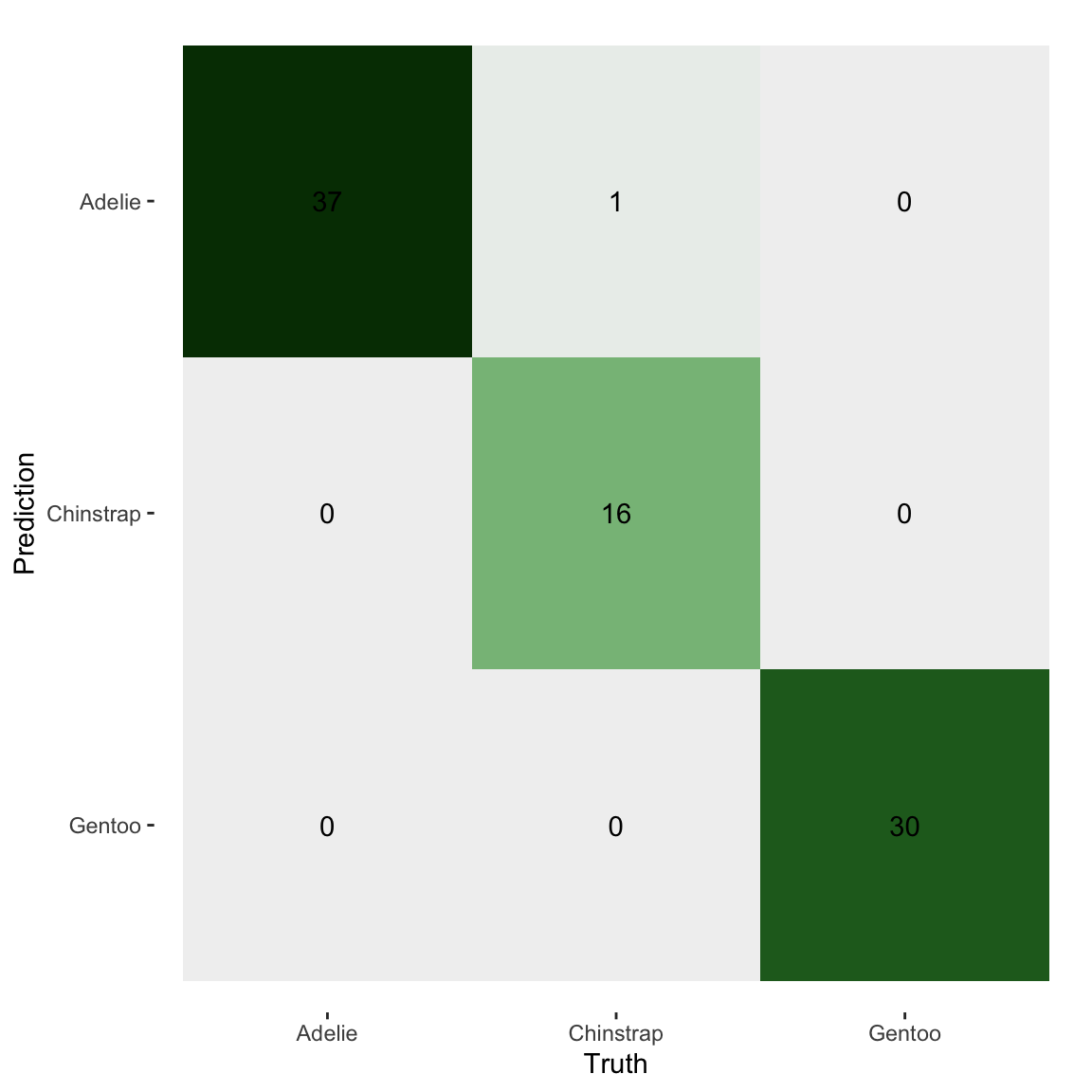
penguins |>
mutate(pred = as.factor(pred)) |>
conf_mat(species, pred) |>
autoplot(type = 'heatmap') +
scale_fill_continuous_diverging("Purple-Green")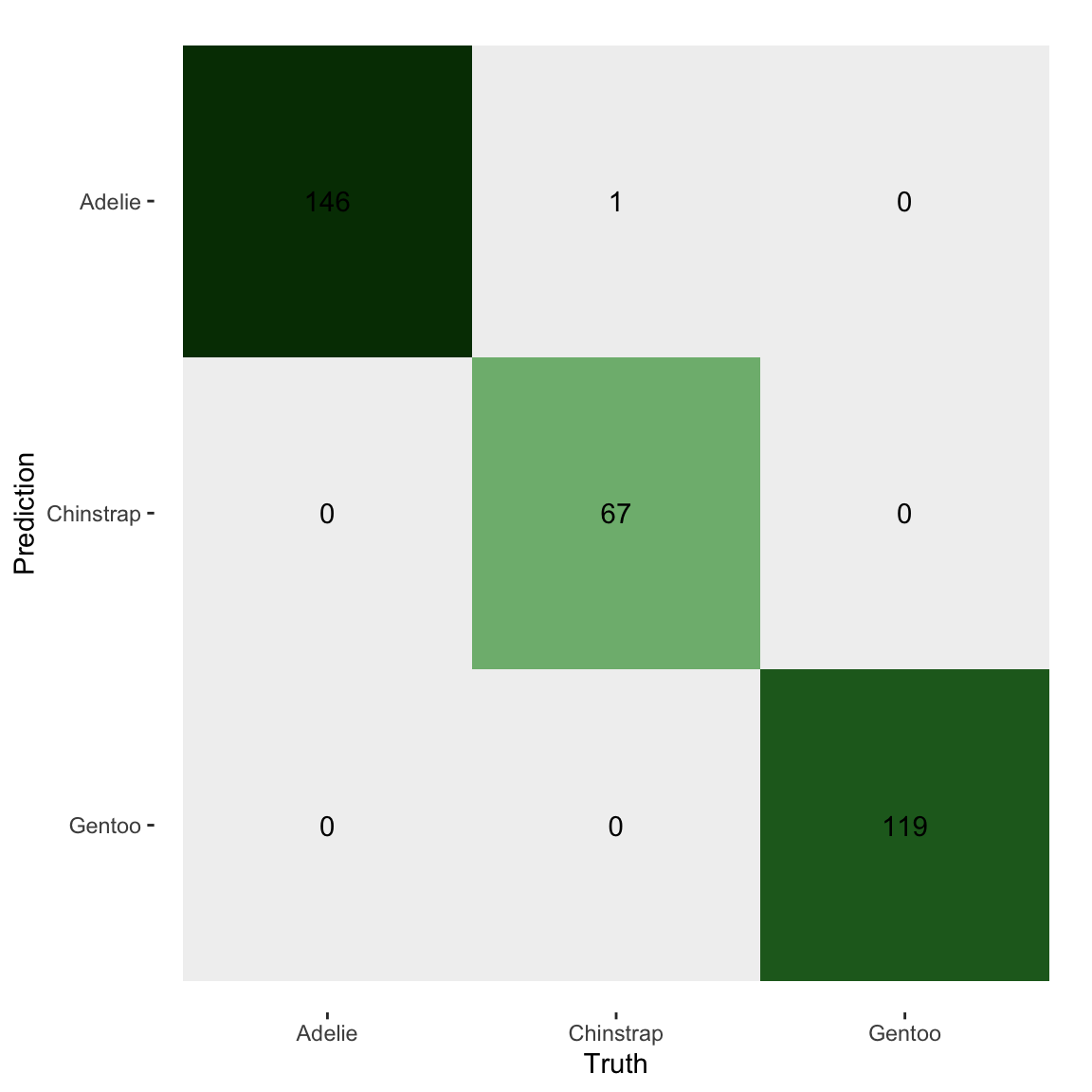
# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 bal_accuracy macro 0.987last_fit fits on the training split and evaluates on the test split# A tibble: 1 × 4
.metric .estimator .estimate .config
<chr> <chr> <dbl> <chr>
1 bal_accuracy macro 0.987 Preprocessor1_Model1![]()
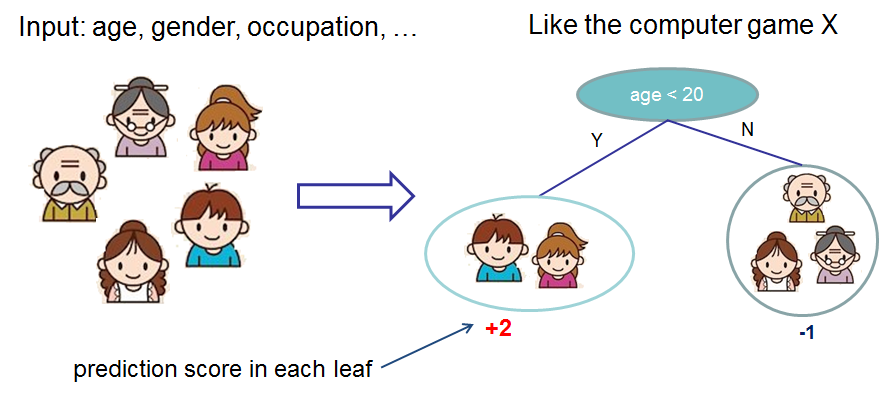
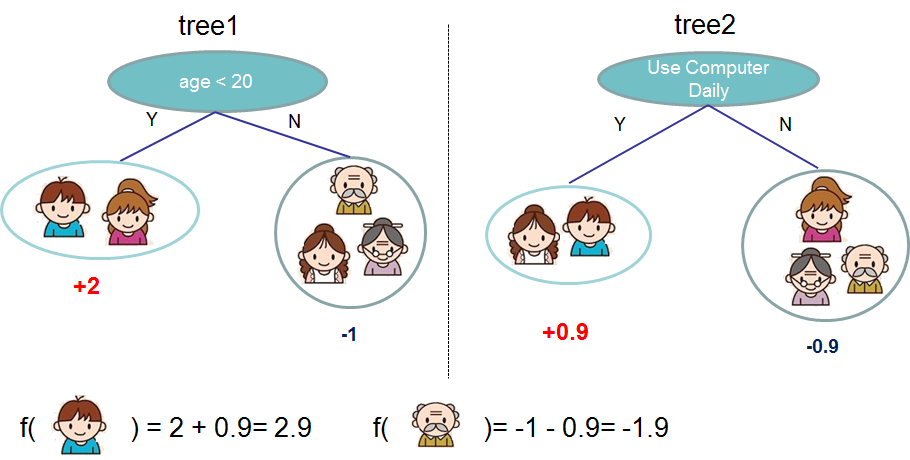
{kind=link}