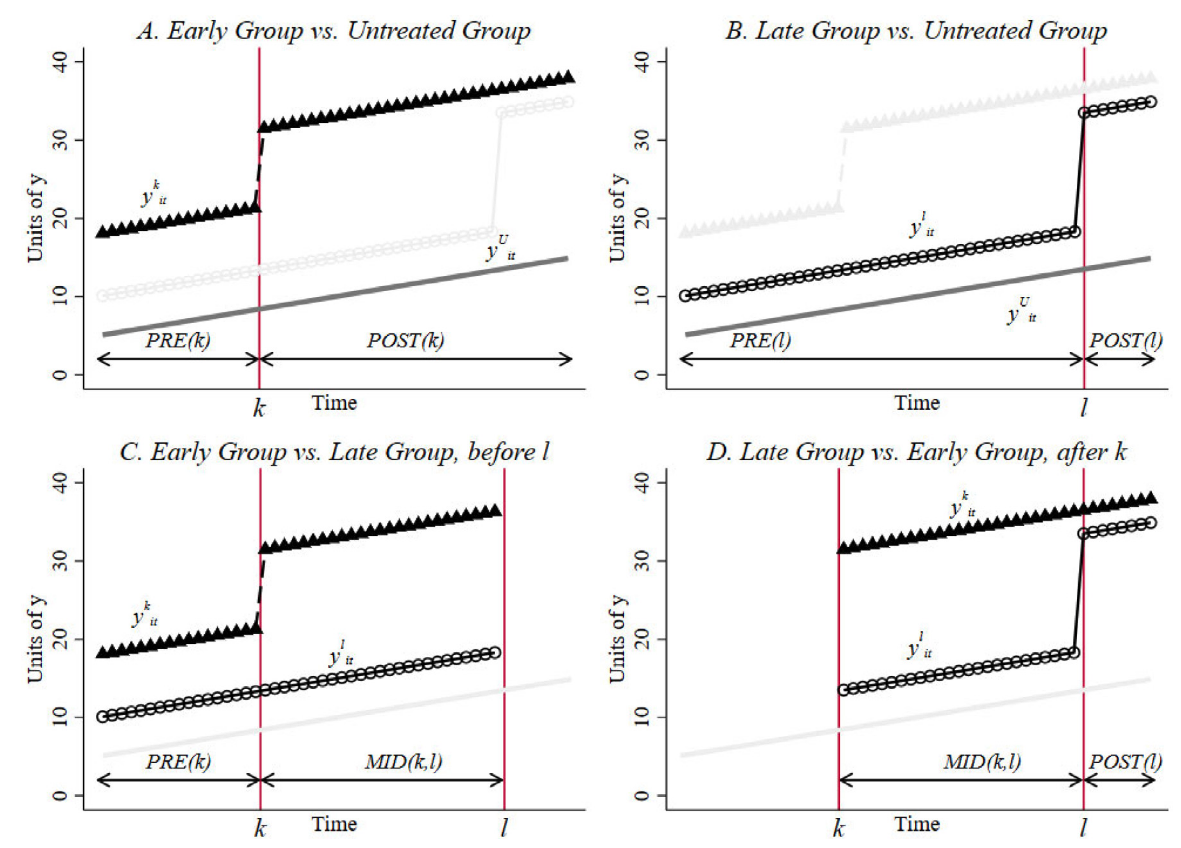
Existing methods for multiple time periods (e.g., Callaway and Sant’Anna 2021) work well if the number of treated units in each group \(g\) is “large” (>5)
library(ggiplot)mod.sunab <-feols(log_streams ~sunab(G, week_num) | id + week_num, data = did_data_staggered )ggiplot(mod.sunab)
References
Callaway, Brantly, and Pedro H. C. Sant’Anna. 2021. “Difference-in-Differences with Multiple Time Periods.”Journal of Econometrics, Themed issue: Treatment effect 1, 225 (2): 200–230. https://doi.org/10.1016/j.jeconom.2020.12.001.
Goodman-Bacon, Andrew. 2021. “Difference-in-Differences with Variation in Treatment Timing.”Journal of Econometrics, Themed issue: Treatment effect 1, 225 (2): 254–77. https://doi.org/10.1016/j.jeconom.2021.03.014.
Rubin, Donald B. 2005. “Causal Inference Using Potential Outcomes: Design, Modeling, Decisions.”Journal of the American Statistical Association 100 (469): 322–31. https://www.jstor.org/stable/27590541.
Sun, Liyang, and Sarah Abraham. 2021. “Estimating Dynamic Treatment Effects in Event Studies with Heterogeneous Treatment Effects.”Journal of Econometrics, Themed issue: Treatment effect 1, 225 (2): 175–99. https://doi.org/10.1016/j.jeconom.2020.09.006.