tibble [284 × 3] (S3: tbl_df/tbl/data.frame)
$ dataset: chr [1:284] "x_shape" "x_shape" "x_shape" "x_shape" ...
$ x : num [1:284] 38.3 35.8 32.8 33.7 37.2 ...
$ y : num [1:284] 92.5 94.1 88.5 88.6 83.7 ...
Visual Channels
Visualizing different magnitudes
We can express the comparison of numbers in multiple ways
Some representations can be interpreted (by humans) more accurately
According to Franconeri et al. (2021) from most to least accurate:
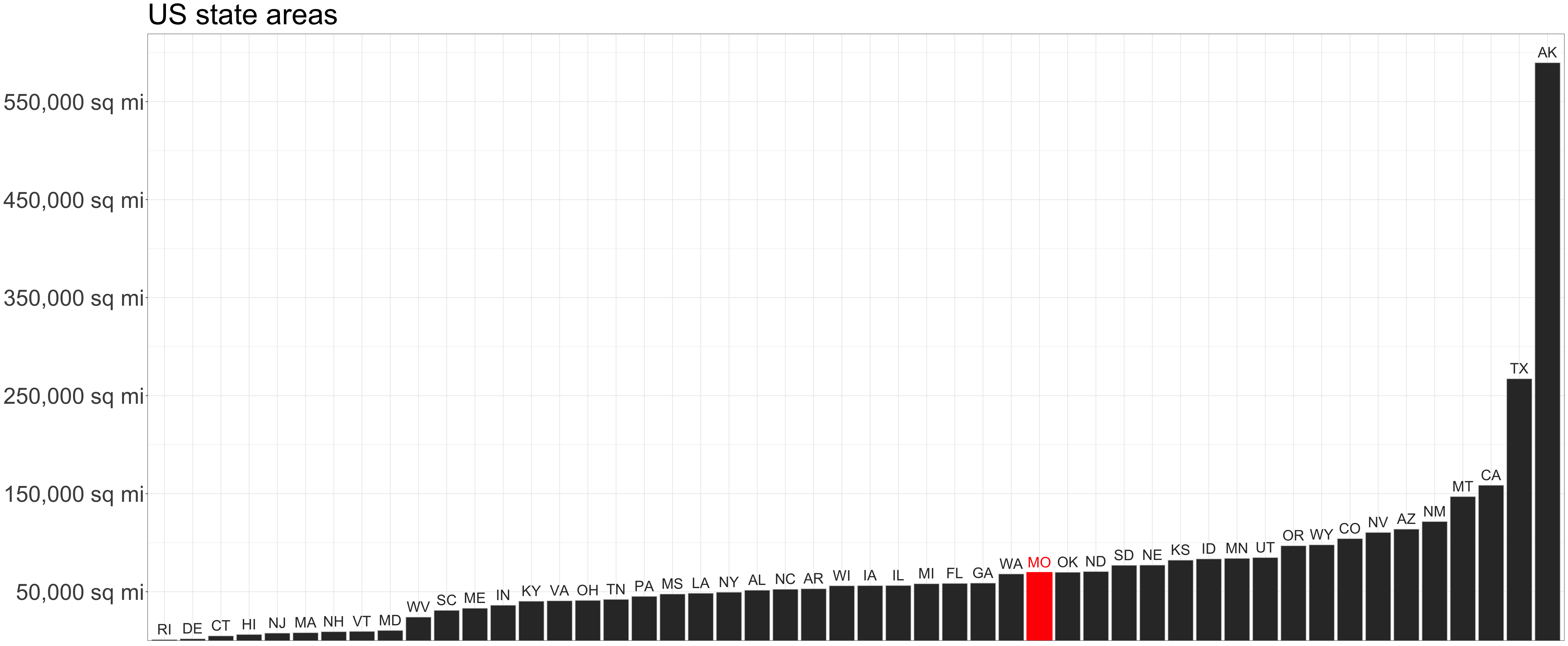
Position
Length
Area
Angle
Intensity
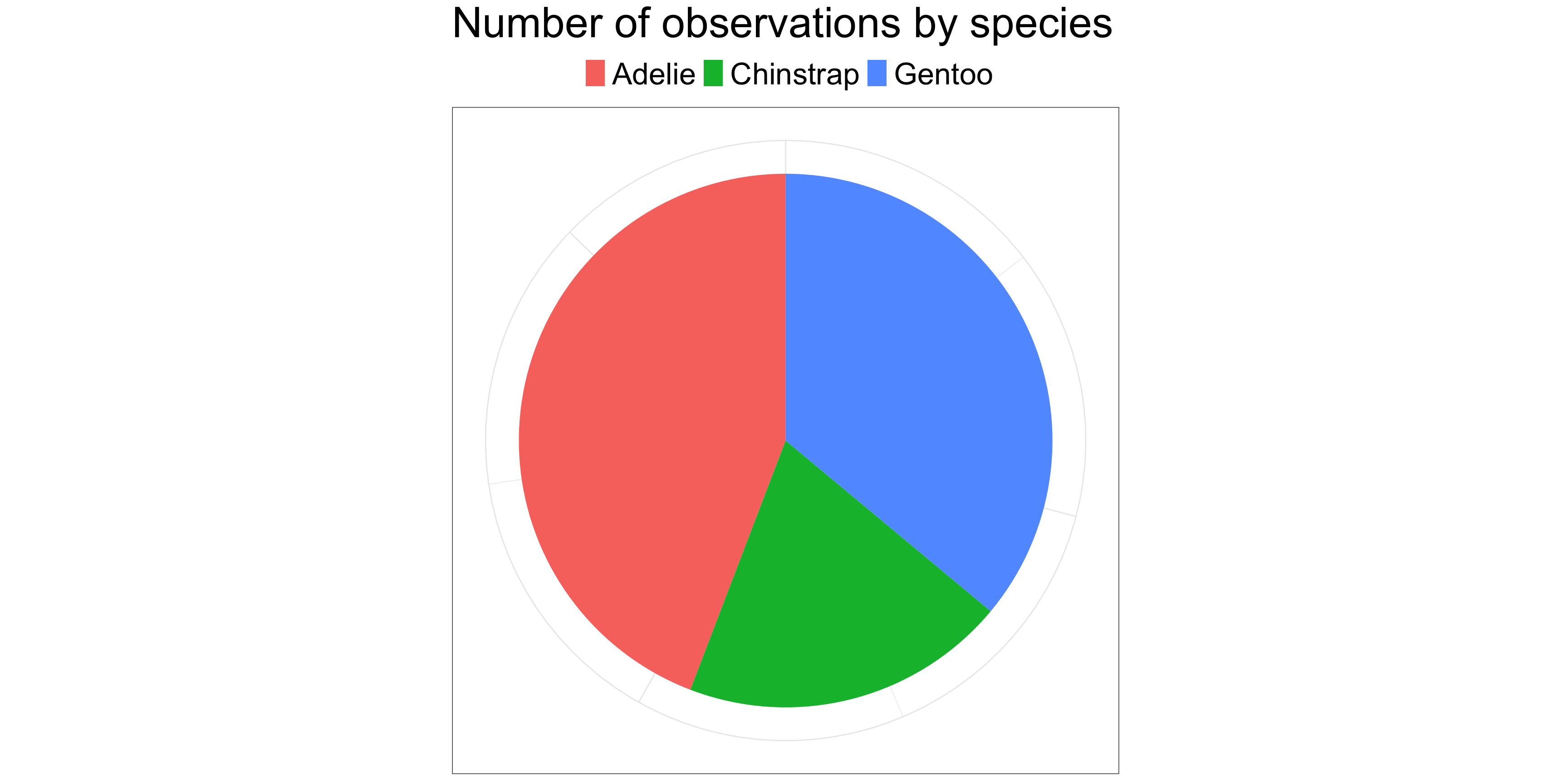
Visualizing “sameness”
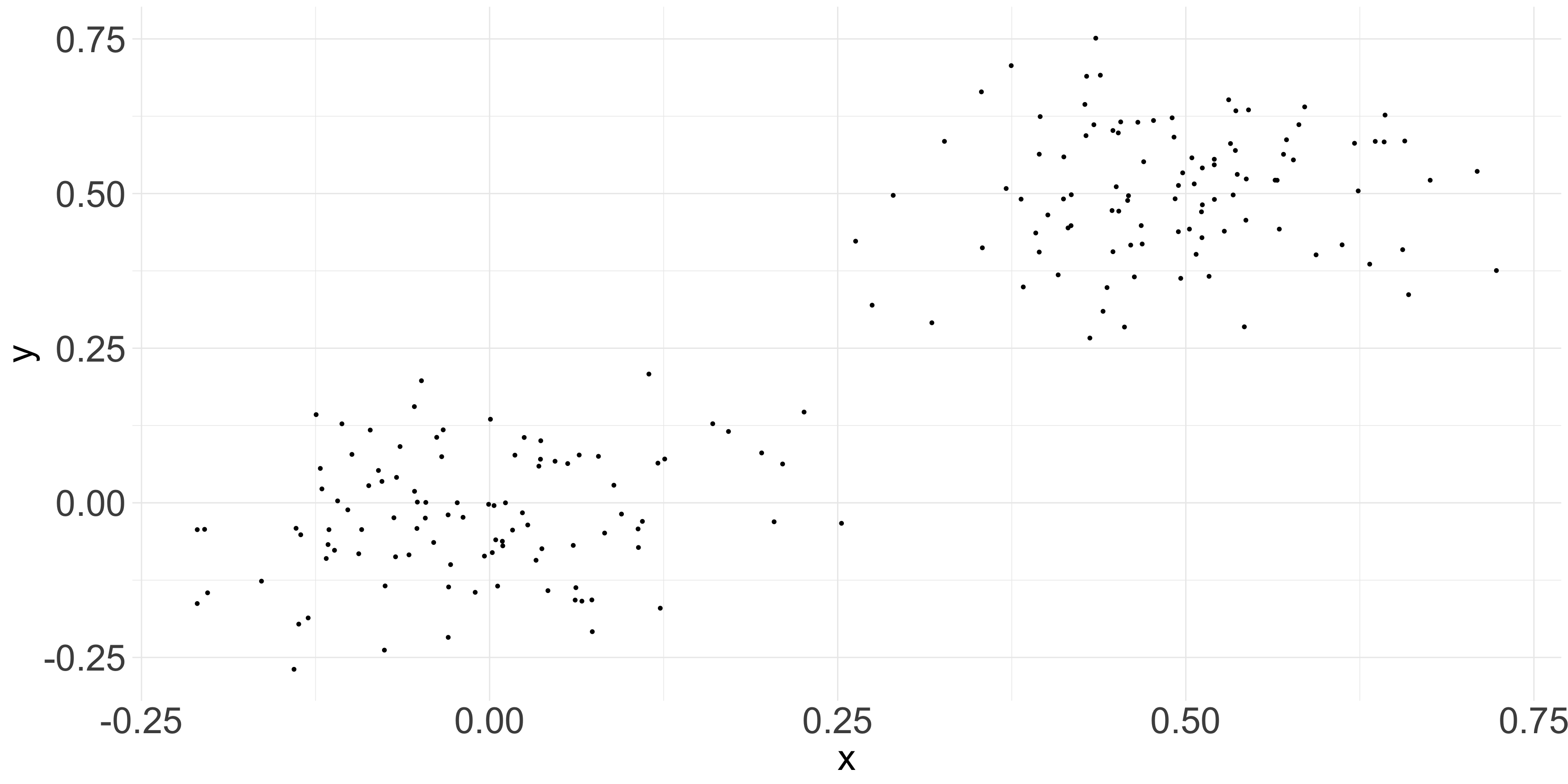
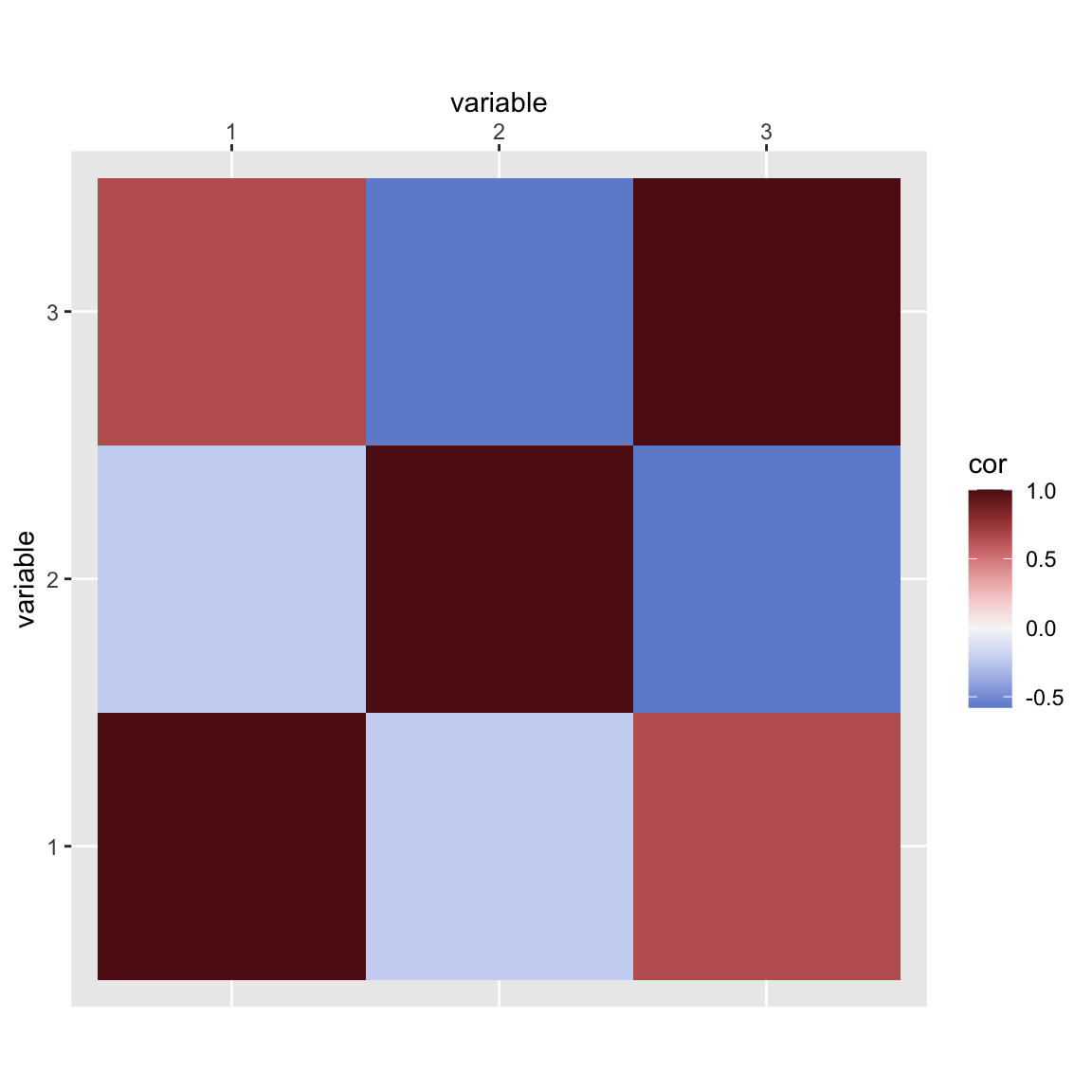
Caution: these can create spurious interpretations
Code
related_data <-data.frame(x =c(rnorm(100, 0, 0.1), rnorm(100, 0.5, 0.1)), y =c(rnorm(100, 0, 0.1), rnorm(100, 0.5, 0.1)))ggplot(related_data, aes(x = x , y = y)) +geom_point(size =1.2) +theme_minimal() +theme(plot.title=element_text(size=35),axis.ticks.x=element_blank(),axis.text=element_text(size=30),axis.title=element_text(size=30) )
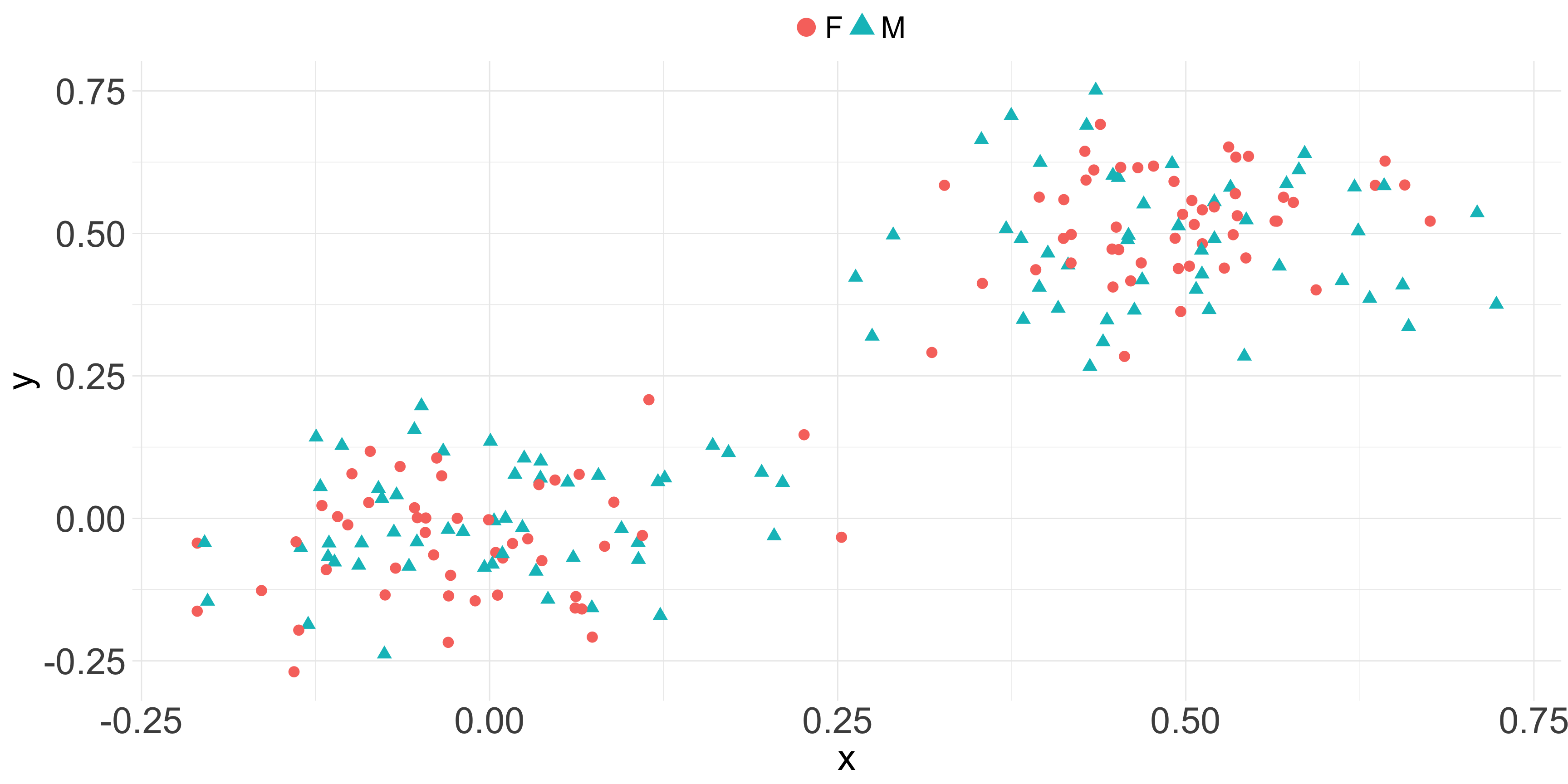
Counteract by using another principle
Code
related_data$g <-as.factor(ifelse(rbinom(200, 1, prob =0.5) ==1, 'F', 'M'))ggplot(related_data, aes(x = x , y = y, color = g, shape = g)) +geom_point(size =4) +guides(colour =guide_legend(override.aes =list(size=7))) +theme_minimal() +theme(plot.title=element_text(size=35),axis.ticks.x=element_blank(),axis.text=element_text(size=30),axis.title=element_text(size=30),legend.title =element_blank(),legend.position ='top',legend.text =element_text(size =25) )
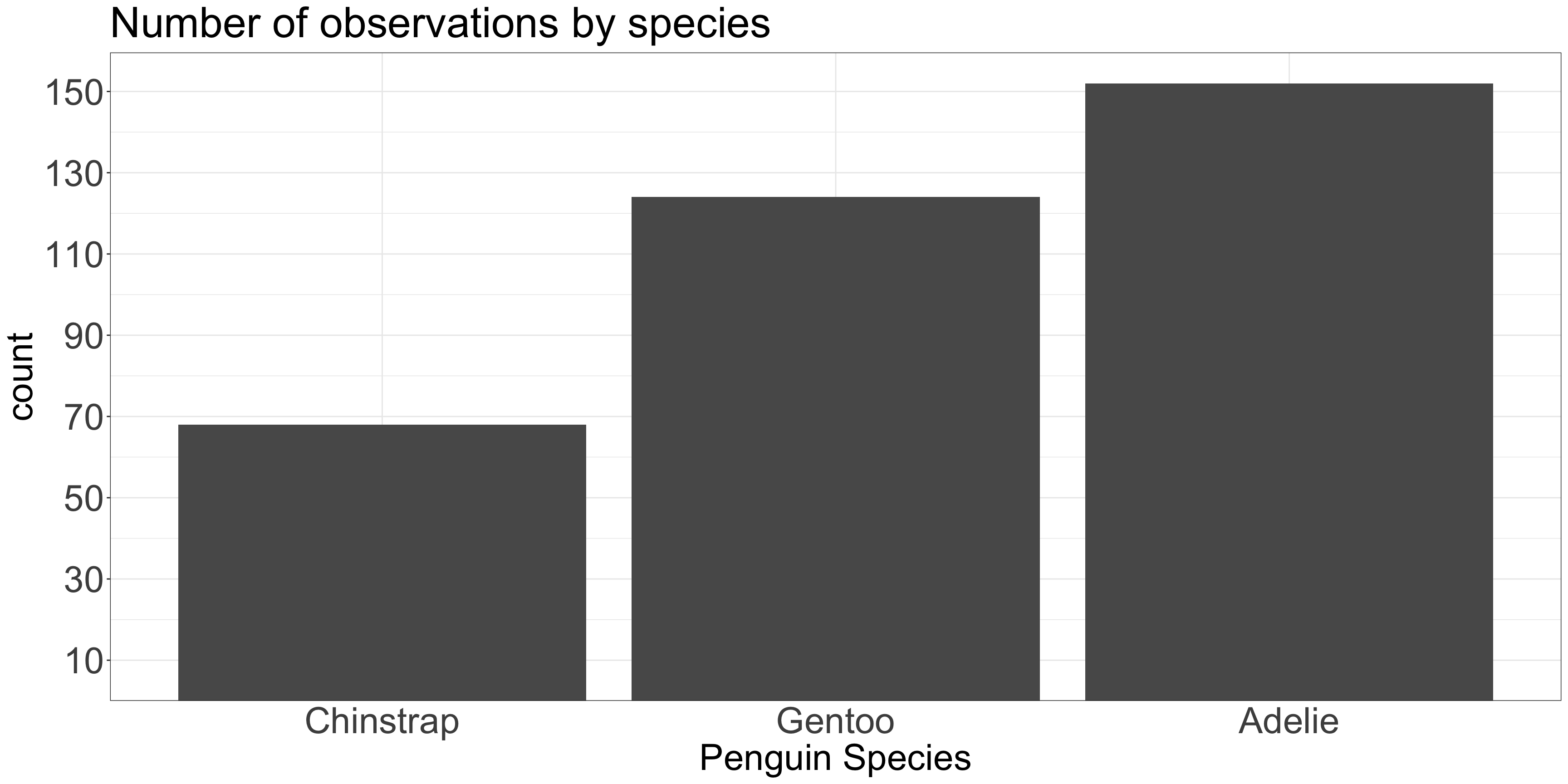
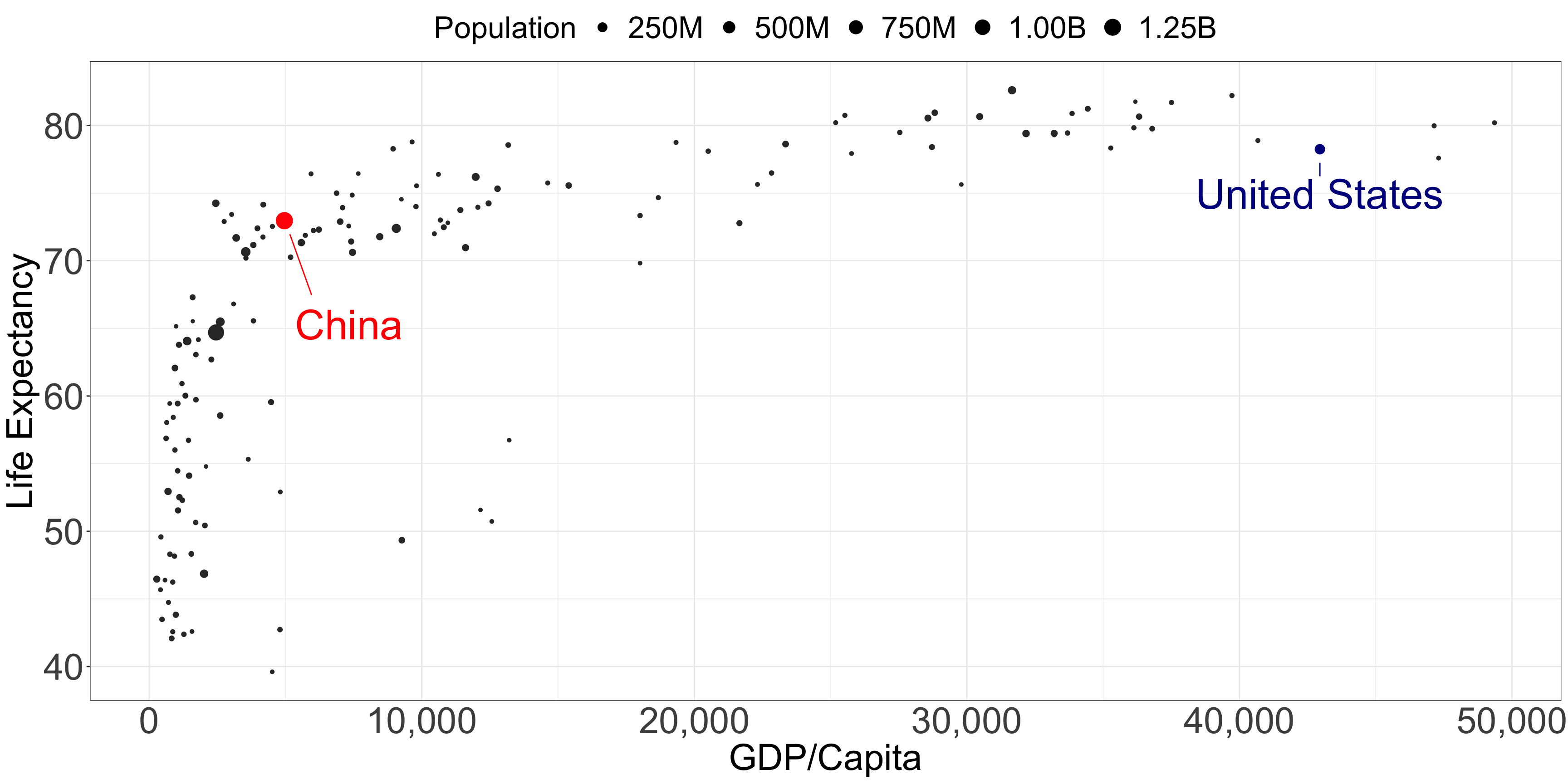
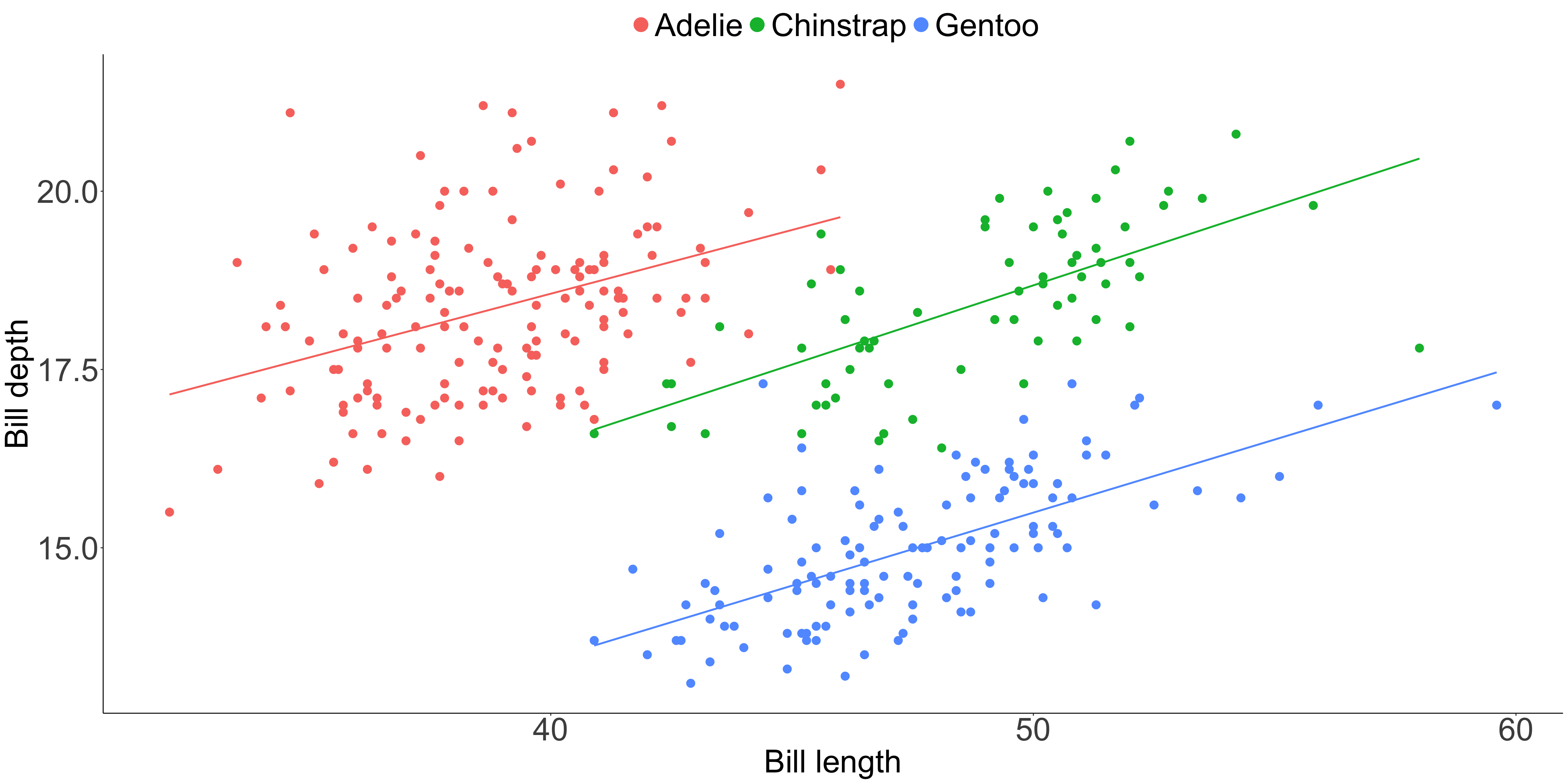
Position is interpreted most accurately
Common y-axis alignment allows for accurate interpretation
Categories in the x-axis sorted by y-axis value
Position should encode the answer to the questions the audience asks
Code
library(palmerpenguins)library(forcats)fct_revfreq <- \(x) fct_rev(fct_infreq(x))ggplot(penguins, aes(x =fct_revfreq(species))) +geom_bar(stat ="count") +scale_y_continuous(expand =expansion(c(0,0.05)),breaks =seq(10,150, by =20)) +labs(title ="Number of observations by species",x ="Penguin Species" ) +theme_bw() +theme(plot.title=element_text(size=35),legend.text=element_text(size=25),axis.ticks.x=element_blank(),axis.text=element_text(size=30),axis.title=element_text(size=30) )
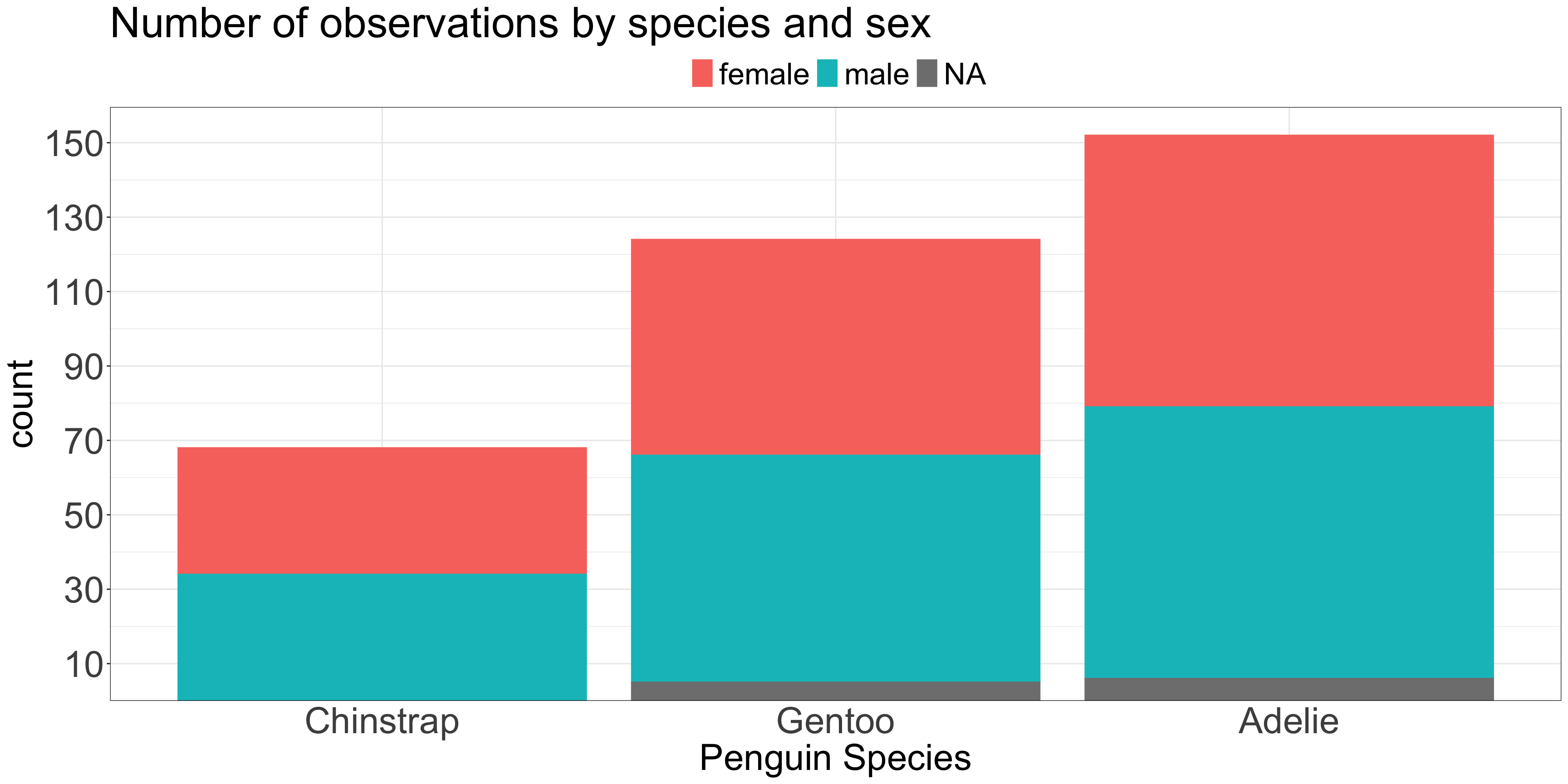
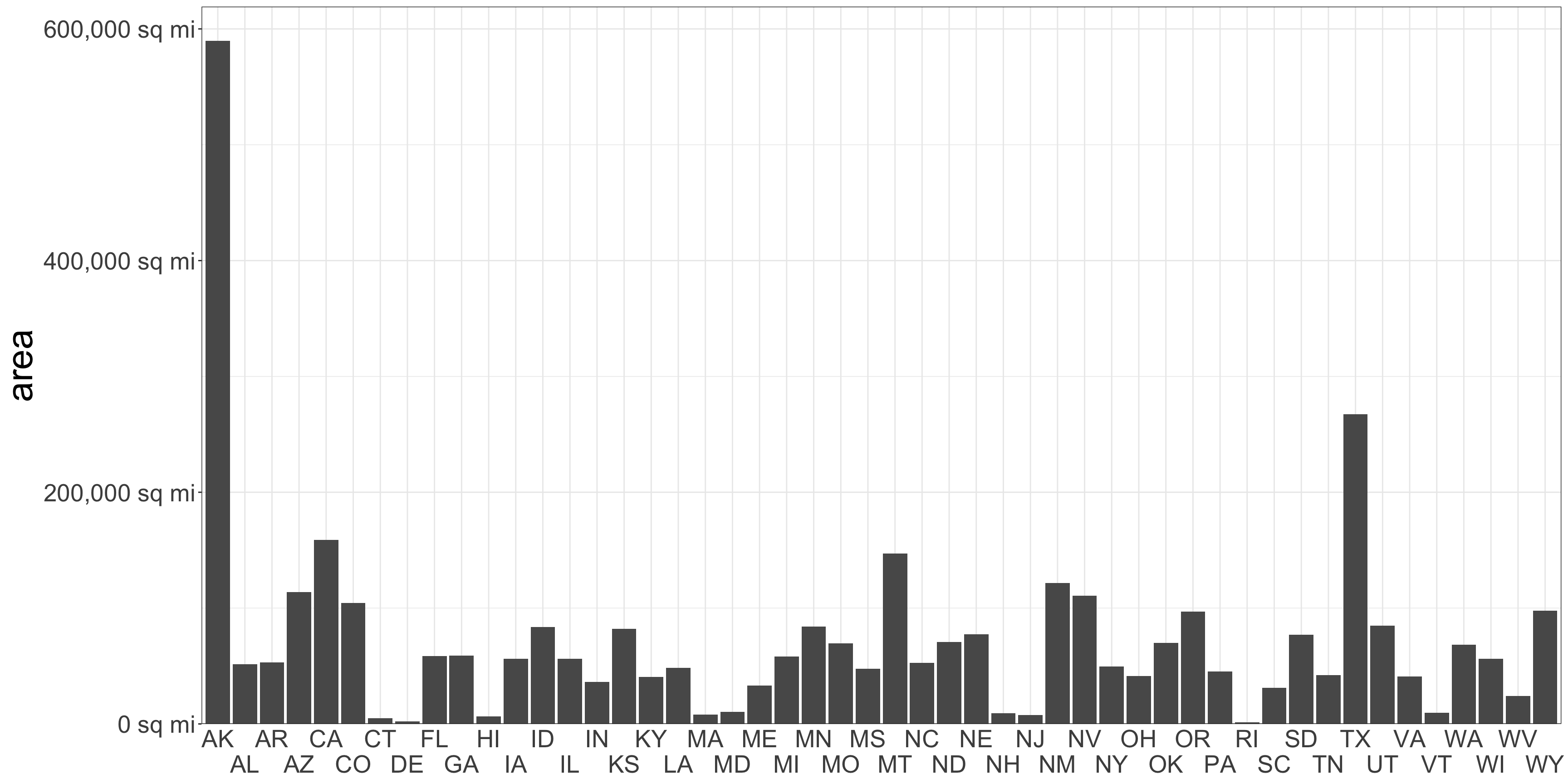
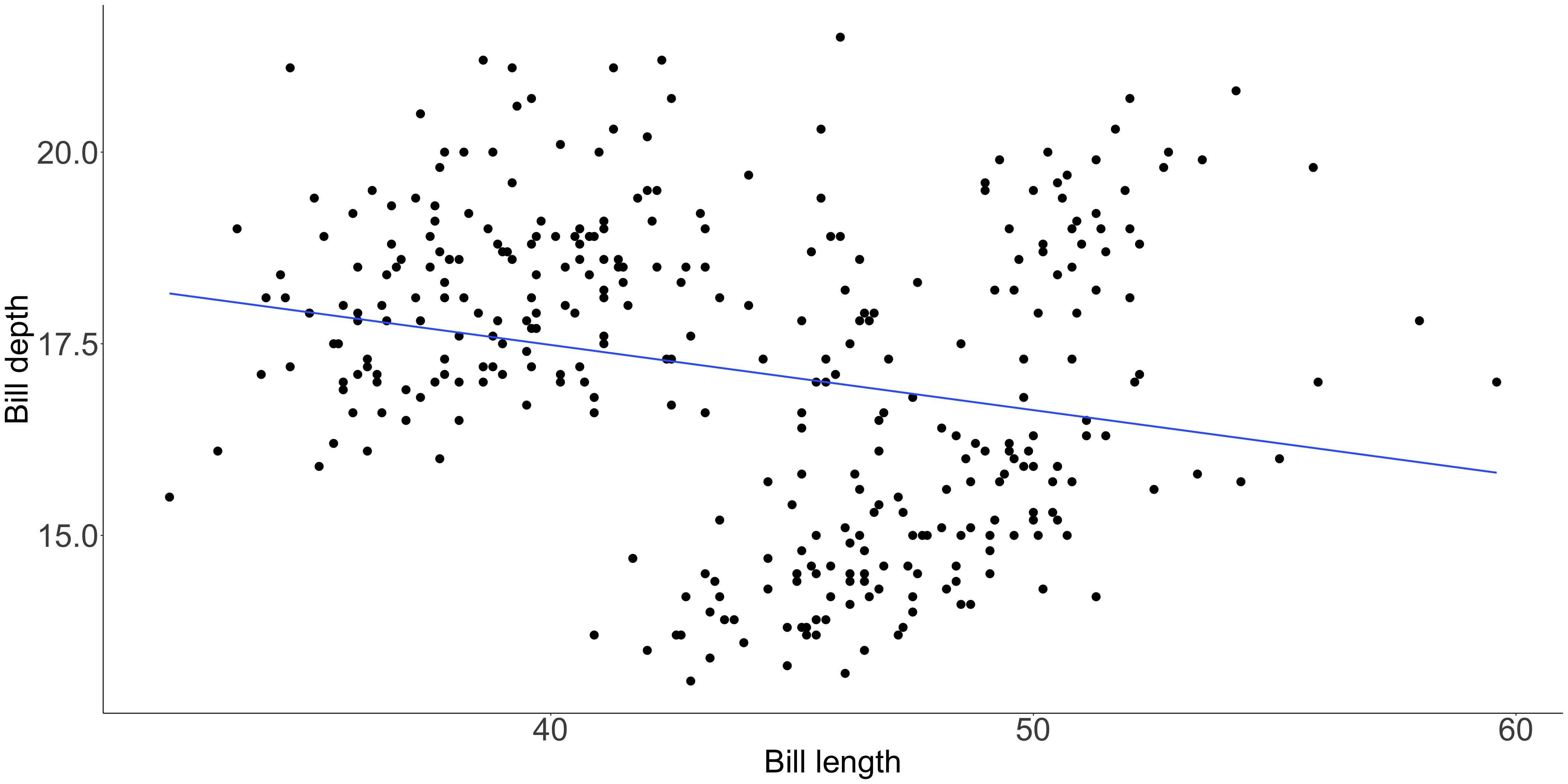
Lengths of unaligned segments are harder to compare
Are there more female Gentoo or female Adelie penguins?
Are there more male or female Gentoo penuins?
Code
ggplot(penguins, aes(x =fct_revfreq(species), color = sex, fill = sex)) +geom_bar(stat ="count") +scale_y_continuous(expand =expansion(c(0,0.05)),breaks =seq(10,150, by =20)) +labs(title ="Number of observations by species and sex",x ="Penguin Species" ) +theme_bw() +theme(plot.title=element_text(size=35),axis.ticks.x=element_blank(),axis.text=element_text(size=30),axis.title=element_text(size=30),legend.position='top',legend.text=element_text(size=25),legend.title=element_blank() )
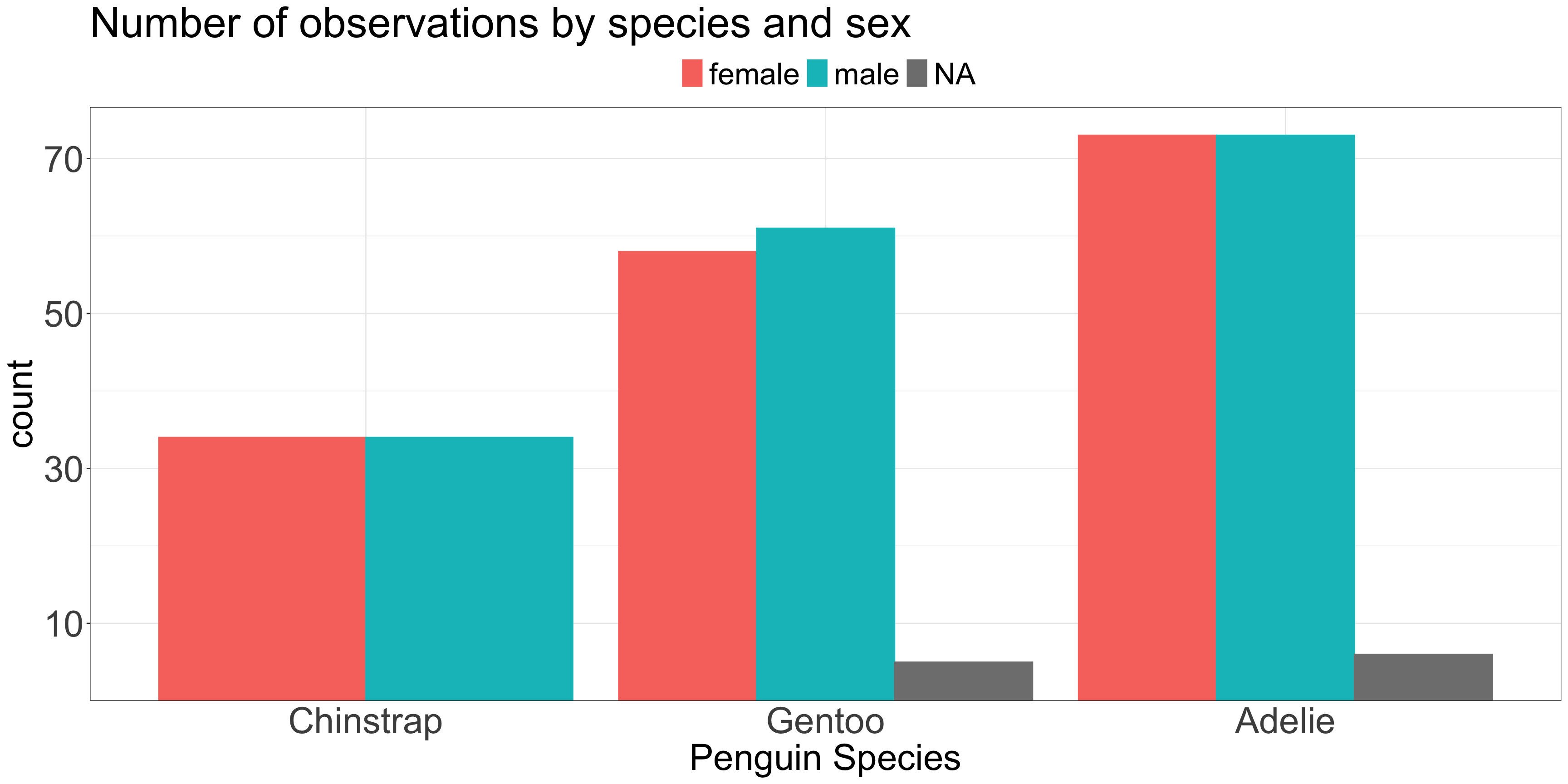
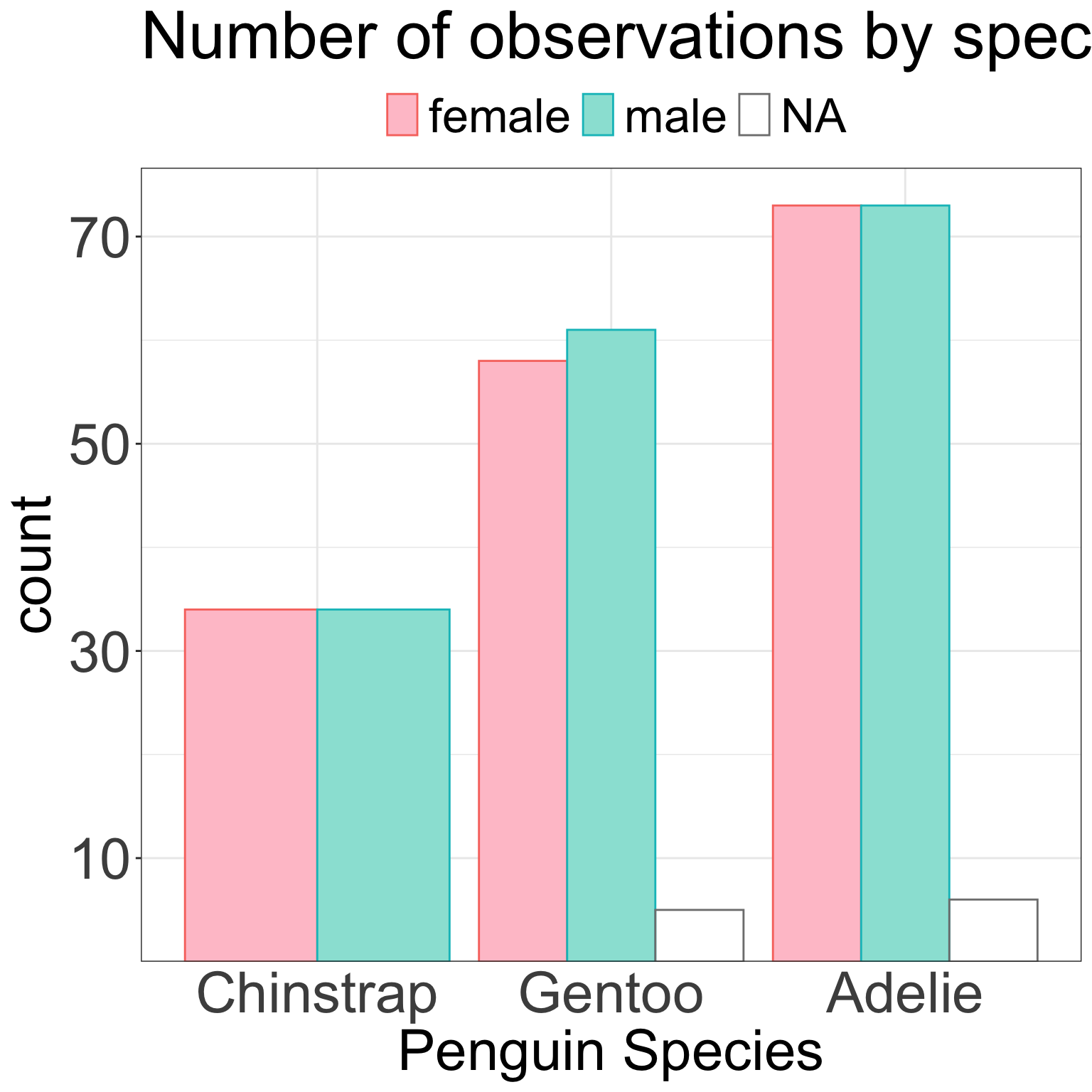
If the total number is not important but sub-group numbers are…
Are there more female Gentoo or female Adelie penguins?
Are there more male or female Gentoo penuins?
Code
ggplot(penguins, aes(x =fct_revfreq(species), color = sex, fill = sex)) +geom_bar(stat ="count", position ='dodge') +scale_y_continuous(expand =expansion(c(0,0.05)),breaks =seq(10,150, by =20)) +labs(title ="Number of observations by species and sex",x ="Penguin Species" ) +theme_bw() +theme(plot.title=element_text(size=35),axis.ticks.x=element_blank(),axis.text=element_text(size=30),axis.title=element_text(size=30),legend.position='top',legend.text=element_text(size=25),legend.title=element_blank() )
Using pre-attentive attributes
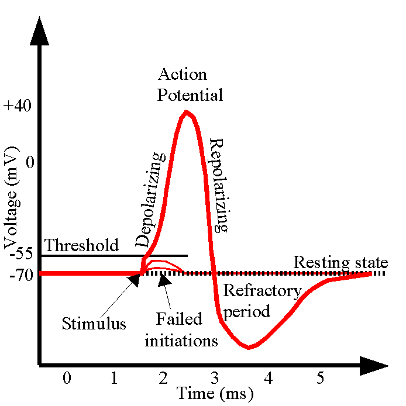
Action potentials are means of communication between neurons in the brain
The probability of firing depends on the strength of the stimulus
The strength of the stimulus is relative to the background
All or nothing process
Once the threshold is exceeded the neuron fires
Takeaway for visualization:
Most important information needs to be “highlighted” relativ to all other information
Rule of thumb: visualize up to 7 groups with colors
More become hard to differentiate
ggplot(penguins, aes(x =fct_revfreq(species), color = sex, fill = sex)) +geom_bar(stat ="count", position ='dodge') +scale_fill_discrete_qualitative("pastel 1") +scale_y_continuous(expand =expansion(c(0,0.05)),breaks =seq(10,150, by =20)) +labs(title ="Number of observations by species and sex",x ="Penguin Species" ) +theme_bw() +theme(plot.title=element_text(size=35),axis.ticks.x=element_blank(),axis.text=element_text(size=30),axis.title=element_text(size=30),legend.position='top',legend.text=element_text(size=25),legend.title=element_blank() )
Color Vision Deficiency
~8% of men and ~0.5% of women have color vision deficiency (CVD) (“color blindness”)
We can simulate CVD using swatchplot(<palette>, cvd = TRUE)
Franconeri, Steven L., Lace M. Padilla, Priti Shah, Jeffrey M. Zacks, and Jessica Hullman. 2021. “The Science of Visual Data Communication: What Works.”Psychological Science in the Public Interest 22 (3): 110–61. https://doi.org/10.1177/15291006211051956.