Introduction to R
Daniel Winkler
The Basics
Why R?
- Well established in business and scientific computing
- Very powerful language
- Express any operation in terms of
- Often complex functions are already implemented
- Very good package manager and ecosystem
- We will use many tools created by companies, universities, and other R community members
- Very good for reproducibility
- Code documents the process
- Should run the same on my and your machine
- Should be easily adaptable to changing data
- Open source
- All packages can be inspected
- Free to install and use on any computer
- Developed (partly) and hosted at WU 😋

What do we need?
- The R interpreter
- The program that “interprets” R code and runs it
- Very bare-bones, essentially just a text field
- Does not store code files for reproducibility
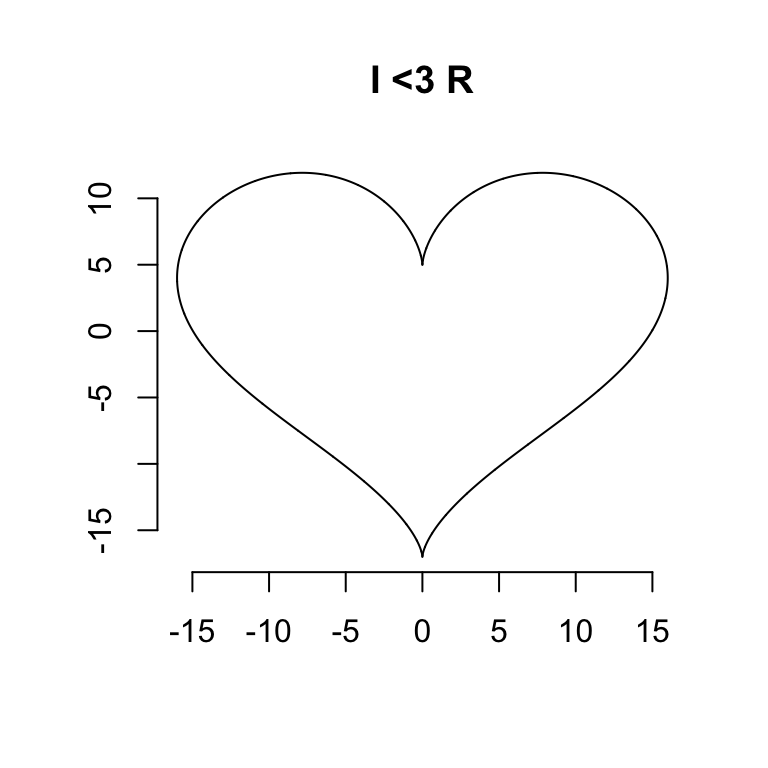
- An Integrated Development Environment (IDE)
- Makes writing and storing R code easier (more fun!)
- Three options compatible with this course:
-
R Studio Desktop (Recommended)
- Focused on R
- Easiest option
-
VS Code
- Recommended if you (plan to) use other languages (Python, C++, Julia, etc.)
- Needs extension for R but works well
-
JupyterLab
- “Notebooks” for R, Python, and Julia
- Output generated directly under code “cells”
-
R Studio Desktop (Recommended)
If you already know R
My favorite R package
- Download the presentation template
my_favorite_r_package.qmdand the bibliography filedata_literacy.bibfrom Canvas - Select a package that was useful to you in the past
- Prepare a short presentation about the package
- Include examples of how to use the package
- Show in which situations that is useful
Basic Workflow (R Studio)
-
Ctrl + Enterto run current line of code (any cursor position)
Basic Workflow (VS Code)
-
Ctrl + Enterto run current line of code (any cursor position)

R Syntax: comments, assignment
Functions
[1] NA[1] NA[1] 6[1] 2 3 4 NA[1] 3 4 5 NA[1] 3 4 5 NA[1] 0.2222222[1] 0.2222222R Syntax: indexing, logic
[1] 1[1] 2 3 NA[1] 2 3[1] 1 3 NA y x
[1,] 1 -0.1264538
[2,] 2 1.1836433
[3,] 3 0.6643714
[4,] NA NA[1] FALSE FALSE TRUE NA[1] FALSE FALSE TRUE NA[1] FALSE TRUE TRUE NA[1] 2 3 NAR Syntax: loops, ranges
[1] "Current y value is: 1"
[1] "Current y value is: 2"
[1] "Current y value is: 3"
[1] "Current y value is: NA"## 'seq_along' returns a vector which indexes the argument
for (i in seq_along(y)) {
print(paste("Current y value is:", y[i]))
}[1] "Current y value is: 1"
[1] "Current y value is: 2"
[1] "Current y value is: 3"
[1] "Current y value is: NA"## set.seed guarantees the same random numbers every time
set.seed(1)
total <- 0
while (total < 1) {
## runif generates random numbers between 0 and 1
total <- total + runif(1)
print(paste("Current total value is:", total))
}[1] "Current total value is: 0.2655086631421"
[1] "Current total value is: 0.63763256277889"
[1] "Current total value is: 1.21048592613079"[1] 1 2 3[1] 10 9 8 7 6 5 4 3[1] 3 5 7 9 11R Syntax: conditional logic
z <- -2:3
for (x in z) {
print(paste("x =", x))
if (x > 0) {
print("x is positive")
} else if (x > 2) {
print("x is greater than 2")
} else if (x < 0) {
print("x is negative")
} else if (x == 0) {
print("x is zero")
}
}[1] "x = -2"
[1] "x is negative"
[1] "x = -1"
[1] "x is negative"
[1] "x = 0"
[1] "x is zero"
[1] "x = 1"
[1] "x is positive"
[1] "x = 2"
[1] "x is positive"
[1] "x = 3"
[1] "x is positive"[1] -2 -1 0[1] 0 1 2 3[1] -2 -1 1 2 3[1] 0 1 2 3Exercise
Write your own function
- The function should take two arguments
aandb - First, check if
aandbhave the same number of elements (see?length)- If they have a different number of elements, return
NA
- If they have a different number of elements, return
- Iterate over the elements of
aandband check which vector’s element is larger (or if they are equal) - If they are equal print the index of the element and “equal”
- If the element in
ais larger print the index of the elemnt and “a larger” - If the element in
bis larger print the index of the elemnt and “b larger”
Example 1
a is: 1 2 3 b is: 1 2 3 4 Result:[1] NAExample 2
a is: 1 2 3 b is: 0 2 4 Result:[1] "1 a larger"[1] "2 equal"[1] "3 b larger"Rectangular data frames: creation and access
x y z
1 -1 3 a
2 0 2 b
3 1 1 <NA>[1] "data.frame"[1] -1 0 1[1] 2 2 2 rsum rdiff
1 2 -4
2 2 -2
3 2 0Rectangular data frames: overview
'data.frame': 3 obs. of 3 variables:
$ x: int -1 0 1
$ y: int 3 2 1
$ z: chr "a" "b" NA x y z
Min. :-1.0 Min. :1.0 Length:3
1st Qu.:-0.5 1st Qu.:1.5 Class :character
Median : 0.0 Median :2.0 Mode :character
Mean : 0.0 Mean :2.0
3rd Qu.: 0.5 3rd Qu.:2.5
Max. : 1.0 Max. :3.0 x y z
1 -1 3 a
2 0 2 b
3 1 1 <NA>Rectangular data frames: Indexing
Rectangular data: adding and removing variables
x y z a
1 -1 3 a -2
2 0 2 b 0
3 1 1 <NA> 2 x y z a b
1 -1 3 a -2 one
2 0 2 b 0 two
3 1 1 <NA> 2 three y z a b
1 3 a -2 one
2 2 b 0 two
3 1 <NA> 2 three y z a b
1 3 a NaN one
2 2 b -Inf two
3 1 <NA> 0.6931472 three y z a b
1 3 a 0.0000000 one
2 2 b -Inf TWO!
3 1 c 0.6931472 threeExercise
Generate your own data
- Look at the helpfiles of
rnorm,runif, andifelse - Create a
data.framewith 10 rows and variablesx, generated usingrunifandy, generated usingrnorm - Add variable
zwhich takes the value1ifxis larger thanyand0otherwise - Create a second
data.framethat holds the rows of the original one for whichz == 1isTRUE. - Remove column
zfrom the seconddata.frame - What happens if you try to create a
data.framewhenxandyhave a differnent number of elements? - What happens if you run the code you wrote for this exercise again (and again)?
- How can you ensure that each run yields the same results?
Reading data
- Please download & unzip the folder found in “data” in Canvas
- We will first use the “penguins” folder which includes the
penguins_rawdata set in multiple file formats
# A tibble: 2 × 18
...1 studyName `Sample Number` Species Region Island Stage `Individual ID`
<chr> <chr> <dbl> <chr> <chr> <chr> <chr> <chr>
1 # this … <NA> NA <NA> <NA> <NA> <NA> <NA>
2 1 PAL0708 1 Adelie… Anvers Torge… Adul… N1A1
# ℹ 10 more variables: `Clutch Completion` <chr>, `Date Egg` <date>,
# `Culmen Length (mm)` <dbl>, `Culmen Depth (mm)` <dbl>,
# `Flipper Length (mm)` <dbl>, `Body Mass (g)` <dbl>, Sex <chr>,
# `Delta 15 N (o/oo)` <dbl>, `Delta 13 C (o/oo)` <dbl>, Comments <chr>Fix the data
- The second row (after the column names) in the
penguins_raw.csvfile is a comment - Look at the help file for the
readr::read_csvfunction (?readr::read_csv) - How can we ignore the comment row?
Reading data: solution
## CSV
penguins_raw <- readr::read_csv(
"data/penguins/penguins_raw.csv",
comment = "#")
head(penguins_raw, 2)# A tibble: 2 × 18
...1 studyName `Sample Number` Species Region Island Stage `Individual ID`
<dbl> <chr> <dbl> <chr> <chr> <chr> <chr> <chr>
1 1 PAL0708 1 Adelie Pe… Anvers Torge… Adul… N1A1
2 2 PAL0708 2 Adelie Pe… Anvers Torge… Adul… N1A2
# ℹ 10 more variables: `Clutch Completion` <chr>, `Date Egg` <date>,
# `Culmen Length (mm)` <dbl>, `Culmen Depth (mm)` <dbl>,
# `Flipper Length (mm)` <dbl>, `Body Mass (g)` <dbl>, Sex <chr>,
# `Delta 15 N (o/oo)` <dbl>, `Delta 13 C (o/oo)` <dbl>, Comments <chr># A tibble: 1 × 1
...1
<dbl>
1 1spc_tbl_ [344 × 18] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
$ ...1 : num [1:344] 1 2 3 4 5 6 7 8 9 10 ...
$ studyName : chr [1:344] "PAL0708" "PAL0708" "PAL0708" "PAL0708" ...
$ Sample Number : num [1:344] 1 2 3 4 5 6 7 8 9 10 ...
$ Species : chr [1:344] "Adelie Penguin (Pygoscelis adeliae)" "Adelie Penguin (Pygoscelis adeliae)" "Adelie Penguin (Pygoscelis adeliae)" "Adelie Penguin (Pygoscelis adeliae)" ...
$ Region : chr [1:344] "Anvers" "Anvers" "Anvers" "Anvers" ...
$ Island : chr [1:344] "Torgersen" "Torgersen" "Torgersen" "Torgersen" ...
$ Stage : chr [1:344] "Adult, 1 Egg Stage" "Adult, 1 Egg Stage" "Adult, 1 Egg Stage" "Adult, 1 Egg Stage" ...
$ Individual ID : chr [1:344] "N1A1" "N1A2" "N2A1" "N2A2" ...
$ Clutch Completion : chr [1:344] "Yes" "Yes" "Yes" "Yes" ...
$ Date Egg : Date[1:344], format: "2007-11-11" "2007-11-11" ...
$ Culmen Length (mm) : num [1:344] 39.1 39.5 40.3 NA 36.7 39.3 38.9 39.2 34.1 42 ...
$ Culmen Depth (mm) : num [1:344] 18.7 17.4 18 NA 19.3 20.6 17.8 19.6 18.1 20.2 ...
$ Flipper Length (mm): num [1:344] 181 186 195 NA 193 190 181 195 193 190 ...
$ Body Mass (g) : num [1:344] 3750 3800 3250 NA 3450 ...
$ Sex : chr [1:344] "MALE" "FEMALE" "FEMALE" NA ...
$ Delta 15 N (o/oo) : num [1:344] NA 8.95 8.37 NA 8.77 ...
$ Delta 13 C (o/oo) : num [1:344] NA -24.7 -25.3 NA -25.3 ...
$ Comments : chr [1:344] "Not enough blood for isotopes." NA NA "Adult not sampled." ...
- attr(*, "spec")=
.. cols(
.. ...1 = col_double(),
.. studyName = col_character(),
.. `Sample Number` = col_double(),
.. Species = col_character(),
.. Region = col_character(),
.. Island = col_character(),
.. Stage = col_character(),
.. `Individual ID` = col_character(),
.. `Clutch Completion` = col_character(),
.. `Date Egg` = col_date(format = ""),
.. `Culmen Length (mm)` = col_double(),
.. `Culmen Depth (mm)` = col_double(),
.. `Flipper Length (mm)` = col_double(),
.. `Body Mass (g)` = col_double(),
.. Sex = col_character(),
.. `Delta 15 N (o/oo)` = col_double(),
.. `Delta 13 C (o/oo)` = col_double(),
.. Comments = col_character()
.. )
- attr(*, "problems")=<externalptr> Reading data: other file formats
- The
readxlpackage provides functions for reading Excel files
# A tibble: 2 × 18
...1 studyName `Sample Number` Species Region Island Stage `Individual ID`
<chr> <chr> <dbl> <chr> <chr> <chr> <chr> <chr>
1 1 PAL0708 1 Adelie Pe… Anvers Torge… Adul… N1A1
2 2 PAL0708 2 Adelie Pe… Anvers Torge… Adul… N1A2
# ℹ 10 more variables: `Clutch Completion` <chr>, `Date Egg` <dttm>,
# `Culmen Length (mm)` <dbl>, `Culmen Depth (mm)` <dbl>,
# `Flipper Length (mm)` <dbl>, `Body Mass (g)` <dbl>, Sex <chr>,
# `Delta 15 N (o/oo)` <dbl>, `Delta 13 C (o/oo)` <dbl>, Comments <chr>## Read a subset
penguins_subset <- readxl::read_excel("data/penguins/penguins_raw.xlsx", sheet = "Sheet1", range = "B1:O345")
head(penguins_subset, 2)# A tibble: 2 × 14
studyName `Sample Number` Species Region Island Stage `Individual ID`
<chr> <dbl> <chr> <chr> <chr> <chr> <chr>
1 PAL0708 1 Adelie Penguin … Anvers Torge… Adul… N1A1
2 PAL0708 2 Adelie Penguin … Anvers Torge… Adul… N1A2
# ℹ 7 more variables: `Clutch Completion` <chr>, `Date Egg` <dttm>,
# `Culmen Length (mm)` <dbl>, `Culmen Depth (mm)` <dbl>,
# `Flipper Length (mm)` <dbl>, `Body Mass (g)` <dbl>, Sex <chr>Reading data: other file formats
- The
havenpackage provides functions for reading SPSS, Stata, and SAS files - It looks like SPSS does not support spaces in column names so this is slightly different
# A tibble: 2 × 17
study_name sample_number species region island stage individual_id
<chr> <dbl> <chr> <chr> <chr> <chr> <chr>
1 PAL0708 1 Adelie Penguin (Py… Anvers Torge… Adul… N1A1
2 PAL0708 2 Adelie Penguin (Py… Anvers Torge… Adul… N1A2
# ℹ 10 more variables: clutch_completion <chr>, date_egg <date>,
# culmen_length_mm <dbl>, culmen_depth_mm <dbl>, flipper_length_mm <dbl>,
# body_mass_g <dbl>, sex <chr>, delta_15_n_o_oo <dbl>, delta_13_c_o_oo <dbl>,
# comments <chr>Reading big data: the arrow package
- The
arrowpackage provides functions for reading Parquet and Feather files - Optimized formats used in many data science projects
- Provides facility to read from “object storage” (e.g., Amazon S3)
The major benefits of object storage are the virtually unlimited scalability and the lower cost of storing large volumes of data for use cases such as data lakes, cloud native applications, analytics, log files, and machine learning (ML). 1
- Rule of thumb:
- use
parquetfor large files and long term storage- optimized file size
- use
featherfor optimized reading and short term storage- memory layout the same as in the process
- use
Reading big data: the arrow package
penguins_raw <- arrow::read_parquet("data/penguins/penguins_raw.parquet")
penguins_raw <- arrow::read_feather("data/penguins/penguins_raw.feather")
head(penguins_raw, 2)# A tibble: 2 × 17
studyName `Sample Number` Species Region Island Stage `Individual ID`
<chr> <dbl> <chr> <chr> <chr> <chr> <chr>
1 PAL0708 1 Adelie Penguin … Anvers Torge… Adul… N1A1
2 PAL0708 2 Adelie Penguin … Anvers Torge… Adul… N1A2
# ℹ 10 more variables: `Clutch Completion` <chr>, `Date Egg` <date>,
# `Culmen Length (mm)` <dbl>, `Culmen Depth (mm)` <dbl>,
# `Flipper Length (mm)` <dbl>, `Body Mass (g)` <dbl>, Sex <chr>,
# `Delta 15 N (o/oo)` <dbl>, `Delta 13 C (o/oo)` <dbl>, Comments <chr>- Support for complex data structures
penguin_species_island <- arrow::read_parquet('data/penguins/penguin_species_nested.parquet')
head(penguin_species_island, 2)# A tibble: 2 × 2
Island data
<chr> <list<tbl_df<Species:character>>>
1 Torgersen [52 × 1]
2 Biscoe [168 × 1]# A tibble: 2 × 2
Island Species
<chr> <chr>
1 Torgersen Adelie Penguin (Pygoscelis adeliae)
2 Torgersen Adelie Penguin (Pygoscelis adeliae)Benchmarks
library(microbenchmark)
microbenchmark(
csv = readr::read_csv("data/penguins/penguins_raw.csv",
show_col_types = FALSE, name_repair = 'minimal'),
parquet = arrow::read_parquet("data/penguins/penguins_raw.parquet"),
feather = arrow::read_feather("data/penguins/penguins_raw.feather")
) Unit: milliseconds
expr min lq mean median uq max neval cld
csv 7.774953 8.164555 8.585466 8.349117 8.586773 11.624443 100 a
parquet 1.783049 1.985671 2.090328 2.074333 2.151618 4.407172 100 b
feather 1.347547 1.463064 1.639503 1.536208 1.606196 4.417750 100 cData types
The most important types of data are:
| Data type | Description |
|---|---|
| Numeric | Approximations of the real numbers, \(\normalsize\mathbb{R}\) (e.g., mileage a car gets: 23.6, 20.9, etc.) |
| Integer | Whole numbers, \(\normalsize\mathbb{Z}\) (e.g., number of sales: 7, 0, 120, 63, etc.) |
| Character | Text data (strings, e.g., product names) |
| Factor | Categorical data for classification (e.g., product groups) |
| Logical | TRUE, FALSE |
| Date | Date variables (e.g., sales dates: 21-06-2015, 06-21-15, 21-Jun-2015, etc.) |
Variables can be converted from one type to another using the appropriate functions (e.g., as.numeric(), as.integer(), as.character(), as.factor(), as.logical(), as.Date()).
Let’s clean up the penguins!
tibble [344 × 17] (S3: tbl_df/tbl/data.frame)
$ studyName : chr [1:344] "PAL0708" "PAL0708" "PAL0708" "PAL0708" ...
$ Sample Number : num [1:344] 1 2 3 4 5 6 7 8 9 10 ...
$ Species : chr [1:344] "Adelie Penguin (Pygoscelis adeliae)" "Adelie Penguin (Pygoscelis adeliae)" "Adelie Penguin (Pygoscelis adeliae)" "Adelie Penguin (Pygoscelis adeliae)" ...
$ Region : chr [1:344] "Anvers" "Anvers" "Anvers" "Anvers" ...
$ Island : chr [1:344] "Torgersen" "Torgersen" "Torgersen" "Torgersen" ...
$ Stage : chr [1:344] "Adult, 1 Egg Stage" "Adult, 1 Egg Stage" "Adult, 1 Egg Stage" "Adult, 1 Egg Stage" ...
$ Individual ID : chr [1:344] "N1A1" "N1A2" "N2A1" "N2A2" ...
$ Clutch Completion : chr [1:344] "Yes" "Yes" "Yes" "Yes" ...
$ Date Egg : Date[1:344], format: "2007-11-11" "2007-11-11" ...
$ Culmen Length (mm) : num [1:344] 39.1 39.5 40.3 NA 36.7 39.3 38.9 39.2 34.1 42 ...
$ Culmen Depth (mm) : num [1:344] 18.7 17.4 18 NA 19.3 20.6 17.8 19.6 18.1 20.2 ...
$ Flipper Length (mm): num [1:344] 181 186 195 NA 193 190 181 195 193 190 ...
$ Body Mass (g) : num [1:344] 3750 3800 3250 NA 3450 ...
$ Sex : chr [1:344] "MALE" "FEMALE" "FEMALE" NA ...
$ Delta 15 N (o/oo) : num [1:344] NA 8.95 8.37 NA 8.77 ...
$ Delta 13 C (o/oo) : num [1:344] NA -24.7 -25.3 NA -25.3 ...
$ Comments : chr [1:344] "Not enough blood for isotopes." NA NA "Adult not sampled." ...
- attr(*, "spec")=
.. cols(
.. studyName = col_character(),
.. `Sample Number` = col_double(),
.. Species = col_character(),
.. Region = col_character(),
.. Island = col_character(),
.. Stage = col_character(),
.. `Individual ID` = col_character(),
.. `Clutch Completion` = col_character(),
.. `Date Egg` = col_date(format = ""),
.. `Culmen Length (mm)` = col_double(),
.. `Culmen Depth (mm)` = col_double(),
.. `Flipper Length (mm)` = col_double(),
.. `Body Mass (g)` = col_double(),
.. Sex = col_character(),
.. `Delta 15 N (o/oo)` = col_double(),
.. `Delta 13 C (o/oo)` = col_double(),
.. Comments = col_character()
.. )- Clean the column names
tibble [344 × 17] (S3: tbl_df/tbl/data.frame)
$ study_name : chr [1:344] "PAL0708" "PAL0708" "PAL0708" "PAL0708" ...
$ sample_number : num [1:344] 1 2 3 4 5 6 7 8 9 10 ...
$ species : chr [1:344] "Adelie Penguin (Pygoscelis adeliae)" "Adelie Penguin (Pygoscelis adeliae)" "Adelie Penguin (Pygoscelis adeliae)" "Adelie Penguin (Pygoscelis adeliae)" ...
$ region : chr [1:344] "Anvers" "Anvers" "Anvers" "Anvers" ...
$ island : chr [1:344] "Torgersen" "Torgersen" "Torgersen" "Torgersen" ...
$ stage : chr [1:344] "Adult, 1 Egg Stage" "Adult, 1 Egg Stage" "Adult, 1 Egg Stage" "Adult, 1 Egg Stage" ...
$ individual_id : chr [1:344] "N1A1" "N1A2" "N2A1" "N2A2" ...
$ clutch_completion: chr [1:344] "Yes" "Yes" "Yes" "Yes" ...
$ date_egg : Date[1:344], format: "2007-11-11" "2007-11-11" ...
$ culmen_length_mm : num [1:344] 39.1 39.5 40.3 NA 36.7 39.3 38.9 39.2 34.1 42 ...
$ culmen_depth_mm : num [1:344] 18.7 17.4 18 NA 19.3 20.6 17.8 19.6 18.1 20.2 ...
$ flipper_length_mm: num [1:344] 181 186 195 NA 193 190 181 195 193 190 ...
$ body_mass_g : num [1:344] 3750 3800 3250 NA 3450 ...
$ sex : chr [1:344] "MALE" "FEMALE" "FEMALE" NA ...
$ delta_15_n_o_oo : num [1:344] NA 8.95 8.37 NA 8.77 ...
$ delta_13_c_o_oo : num [1:344] NA -24.7 -25.3 NA -25.3 ...
$ comments : chr [1:344] "Not enough blood for isotopes." NA NA "Adult not sampled." ...
- attr(*, "spec")=
.. cols(
.. studyName = col_character(),
.. `Sample Number` = col_double(),
.. Species = col_character(),
.. Region = col_character(),
.. Island = col_character(),
.. Stage = col_character(),
.. `Individual ID` = col_character(),
.. `Clutch Completion` = col_character(),
.. `Date Egg` = col_date(format = ""),
.. `Culmen Length (mm)` = col_double(),
.. `Culmen Depth (mm)` = col_double(),
.. `Flipper Length (mm)` = col_double(),
.. `Body Mass (g)` = col_double(),
.. Sex = col_character(),
.. `Delta 15 N (o/oo)` = col_double(),
.. `Delta 13 C (o/oo)` = col_double(),
.. Comments = col_character()
.. )Data-preprocessing: syntax
-
|>is the “pipe” operator- It takes the result of the left side and passes it to the right side as the first argument
- Very useful when “chaining” multiple operations
# A tibble: 2 × 17
study_name sample_number species region island stage individual_id
<chr> <dbl> <chr> <chr> <chr> <chr> <chr>
1 PAL0708 1 Adelie Penguin (Py… Anvers Torge… Adul… N1A1
2 PAL0708 2 Adelie Penguin (Py… Anvers Torge… Adul… N1A2
# ℹ 10 more variables: clutch_completion <chr>, date_egg <date>,
# culmen_length_mm <dbl>, culmen_depth_mm <dbl>, flipper_length_mm <dbl>,
# body_mass_g <dbl>, sex <chr>, delta_15_n_o_oo <dbl>, delta_13_c_o_oo <dbl>,
# comments <chr># A tibble: 2 × 17
study_name sample_number species region island stage individual_id
<chr> <dbl> <chr> <chr> <chr> <chr> <chr>
1 PAL0708 1 Adelie Penguin (Py… Anvers Torge… Adul… N1A1
2 PAL0708 2 Adelie Penguin (Py… Anvers Torge… Adul… N1A2
# ℹ 10 more variables: clutch_completion <chr>, date_egg <date>,
# culmen_length_mm <dbl>, culmen_depth_mm <dbl>, flipper_length_mm <dbl>,
# body_mass_g <dbl>, sex <chr>, delta_15_n_o_oo <dbl>, delta_13_c_o_oo <dbl>,
# comments <chr>Data preprocessing: mutation
- Pkg:
dplyrprovides function fordata.framemanipulation - Pkg:
stringrprovides functions to manipulate strings (characters) - fn:
mutatetakes each row and applies a function to create a new (or overwrite a) column - fn:
selectselects columns
library(dplyr)
library(stringr)
penguins_subset <- penguins |>
mutate(
species = str_split(species, " ", n = 2, simplify = TRUE)[,1],
is_adult = str_detect(str_to_lower(stage), "adult"),
is_female = str_detect(str_to_lower(sex), "female"),
sex = str_to_lower(sex)) |>
select(species, island, sex, is_adult, culmen_length_mm, culmen_depth_mm, is_female)
penguins_subset |> head(2)# A tibble: 2 × 7
species island sex is_adult culmen_length_mm culmen_depth_mm is_female
<chr> <chr> <chr> <lgl> <dbl> <dbl> <lgl>
1 Adelie Torgersen male TRUE 39.1 18.7 FALSE
2 Adelie Torgersen female TRUE 39.5 17.4 TRUE Data preprocessing: multiple columns
#penguins_subset <-
penguins_subset <- penguins_subset |>
mutate(
across(starts_with('culmen'), \(x) x / 10),
across(species:sex, as.factor),
across(c('is_adult', 'is_female'), as.numeric)
) |>
mutate_if(is.numeric,
list(scaled = \(x) (x - mean(x, na.rm=TRUE)) / sd(x, na.rm=TRUE))
) |>
rename_with(
\(name) str_replace(name, "mm", "cm"),
starts_with('culmen'))
penguins_subset |> select(-starts_with('is')) |> str()tibble [344 × 6] (S3: tbl_df/tbl/data.frame)
$ species : Factor w/ 3 levels "Adelie","Chinstrap",..: 1 1 1 1 1 1 1 1 1 1 ...
$ sex : Factor w/ 2 levels "female","male": 2 1 1 NA 1 2 1 2 NA NA ...
$ culmen_length_cm : num [1:344] 3.91 3.95 4.03 NA 3.67 3.93 3.89 3.92 3.41 4.2 ...
$ culmen_depth_cm : num [1:344] 1.87 1.74 1.8 NA 1.93 2.06 1.78 1.96 1.81 2.02 ...
$ culmen_length_cm_scaled: num [1:344] -0.883 -0.81 -0.663 NA -1.323 ...
$ culmen_depth_cm_scaled : num [1:344] 0.784 0.126 0.43 NA 1.088 ...
- attr(*, "spec")=
.. cols(
.. studyName = col_character(),
.. `Sample Number` = col_double(),
.. Species = col_character(),
.. Region = col_character(),
.. Island = col_character(),
.. Stage = col_character(),
.. `Individual ID` = col_character(),
.. `Clutch Completion` = col_character(),
.. `Date Egg` = col_date(format = ""),
.. `Culmen Length (mm)` = col_double(),
.. `Culmen Depth (mm)` = col_double(),
.. `Flipper Length (mm)` = col_double(),
.. `Body Mass (g)` = col_double(),
.. Sex = col_character(),
.. `Delta 15 N (o/oo)` = col_double(),
.. `Delta 13 C (o/oo)` = col_double(),
.. Comments = col_character()
.. )Hint: figuring out what is going on
- Split the problem into smaller pieces
\(name) str_replace(name, "mm", "cm")[1] "acmm"- Check help files
\(\rightarrow\) closures are functions
- See if you can produce some outcome on the reduced problem
Hint: read the source code
- This is only useful if a function is pure R code
function (string, pattern, replacement)
{
if (!missing(replacement) && is_replacement_fun(replacement)) {
replacement <- as_function(replacement)
return(str_transform(string, pattern, replacement))
}
check_lengths(string, pattern, replacement)
switch(type(pattern), empty = no_empty(), bound = no_boundary(),
fixed = stri_replace_first_fixed(string, pattern, replacement,
opts_fixed = opts(pattern)), coll = stri_replace_first_coll(string,
pattern, replacement, opts_collator = opts(pattern)),
regex = stri_replace_first_regex(string, pattern, fix_replacement(replacement),
opts_regex = opts(pattern)))
}
<bytecode: 0x10ec684a8>
<environment: namespace:stringr>Aside: functions and variable names
- Common mistake that leads to cryptic error:
Reducing rows: filtering
- Create different subsets of data
- “Filter in” (not out) \(\rightarrow\)
TRUErows remain
Reducing rows: summarizing
- Calculate any appropriate summary for a variable
# A tibble: 1 × 1
avg_weight
<dbl>
1 4202.- Calculate the summary for each group
penguins_summary <- penguins_subset |>
drop_na(culmen_length_cm) |>
group_by(species, sex) |>
summarize(avg_clength = mean(culmen_length_cm))
penguins_summary# A tibble: 8 × 3
# Groups: species [3]
species sex avg_clength
<fct> <fct> <dbl>
1 Adelie female 3.73
2 Adelie male 4.04
3 Adelie <NA> 3.78
4 Chinstrap female 4.66
5 Chinstrap male 5.11
6 Gentoo female 4.56
7 Gentoo male 4.95
8 Gentoo <NA> 4.56Pivot tables
# A tibble: 3 × 4
sex Adelie Chinstrap Gentoo
<fct> <dbl> <dbl> <dbl>
1 female 3.73 4.66 4.56
2 male 4.04 5.11 4.95
3 <NA> 3.78 NA 4.56penguins_wide <- penguins_subset |>
drop_na(culmen_length_cm) |>
select(culmen_length_cm, species, sex) |>
pivot_wider(values_from = culmen_length_cm, names_from = species, values_fn = mean) |>
arrange(sex) |>
select(sex, Adelie, Chinstrap, Gentoo)
penguins_wide# A tibble: 3 × 4
sex Adelie Chinstrap Gentoo
<fct> <dbl> <dbl> <dbl>
1 female 3.73 4.66 4.56
2 male 4.04 5.11 4.95
3 <NA> 3.78 NA 4.56# A tibble: 9 × 3
sex species avg_clength
<fct> <chr> <dbl>
1 female Adelie 3.73
2 female Chinstrap 4.66
3 female Gentoo 4.56
4 male Adelie 4.04
5 male Chinstrap 5.11
6 male Gentoo 4.95
7 <NA> Adelie 3.78
8 <NA> Chinstrap NA
9 <NA> Gentoo 4.56Exercise
Become the Ornithologist
- Read the
penguins_raw.featherfile - Remove all whitespace and special characters from the column names
- Calculate the body mass for each penguin in kg
- Create a pivot-table with the median (
?median) body mass for each species on each island- the island names should be in the first column
- the species names should be the remaining columns
- Repeat the analysis but only for female penguins
Become the music manager
- Read the
top10_charts.csvinchart_data - What is the range of dates in this dataset? (Hint:
?min,?max) - What is the top region in terms of streams overall? (Hint:
?slice_max) - Create a pivot-table of the total streams (in this dataset) within a region on a given day (1st column day, remaining columns region names, values total streams)
Merging data I
- Often we have two separate datasets with corresponding groups of rows
- Streams, trackID in
top10_charts.csvand Song metadata, trackID intop10_meta.csv - purchaseid, customerid in
noahs-orders.csvand productid, purchaseid innoahs-orders_items.csvand customerid, customer metadata innoahs-customers.csv
- Streams, trackID in
- Combine data using
joins
charts <- readr::read_csv("data/chart_data/top10_charts.csv")
songs <- readr::read_csv("data/chart_data/top10_meta.csv")
str(charts, give.attr=FALSE)spc_tbl_ [7,320 × 7] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
$ trackID : chr [1:7320] "012iHyRvQQquWQGUTYvDxy" "017PF4Q3l4DBUiWoXk4OWT" "017PF4Q3l4DBUiWoXk4OWT" "017PF4Q3l4DBUiWoXk4OWT" ...
$ rank : num [1:7320] 7 6 7 7 7 8 9 9 10 10 ...
$ streams : num [1:7320] 26234 4276985 3688979 3255639 3478044 ...
$ day : Date[1:7320], format: "2020-08-14" "2020-03-27" ...
$ dayNumber: num [1:7320] 1318 1178 1179 1180 1181 ...
$ region : chr [1:7320] "at" "global" "global" "global" ...
$ isrc : chr [1:7320] "DEUM72004523" "GBAHT1901303" "GBAHT1901303" "GBAHT1901303" ...spc_tbl_ [347 × 29] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
$ trackID : chr [1:347] "012iHyRvQQquWQGUTYvDxy" "017PF4Q3l4DBUiWoXk4OWT" "01I9AEz658sQnQzCL3K3QG" "033if6Adj8fwBYsQzHOfQ8" ...
$ trackName : chr [1:347] "Fall Auf" "Break My Heart" "HOES UP G'S DOWN" "100k Cash" ...
$ artistName : chr [1:347] "Cro feat. badchieff" "Dua Lipa" "Shirin David" "Capital Bra feat. Samra" ...
$ artistIds : chr [1:347] "3utZ2yeQk0Z3BCOBWP7Vlu,6GoNVmYCl0yUm4pEp80vn6" "6M2wZ9GZgrQXHCFfjv46we" "0JBdTCGs111JKKYfLqOEBa" "4WZGDpNwrC0vNQyl9QzF7d,6h1s4i4XKIYv4ErDelLDN0" ...
$ isrc : chr [1:347] "DEUM72004523" "GBAHT1901303" "DECE72000379" "DECE72000176" ...
$ explicit : num [1:347] 0 0 1 0 0 0 0 1 0 0 ...
$ trackPopularity : num [1:347] 64 83 75 71 69 82 70 74 89 79 ...
$ primary_artistName : chr [1:347] "Cro" "Dua Lipa" "Shirin David" "Capital Bra" ...
$ primary_artistID : chr [1:347] "3utZ2yeQk0Z3BCOBWP7Vlu" "6M2wZ9GZgrQXHCFfjv46we" "0JBdTCGs111JKKYfLqOEBa" "4WZGDpNwrC0vNQyl9QzF7d" ...
$ artistIDs : chr [1:347] "3utZ2yeQk0Z3BCOBWP7Vlu,6GoNVmYCl0yUm4pEp80vn6" "6M2wZ9GZgrQXHCFfjv46we" "0JBdTCGs111JKKYfLqOEBa" "4WZGDpNwrC0vNQyl9QzF7d,6h1s4i4XKIYv4ErDelLDN0" ...
$ albumName : chr [1:347] "Fall Auf" "Future Nostalgia" "HOES UP G'S DOWN" "100k Cash" ...
$ albumID : chr [1:347] "1qdHQo41Vkkgs8HtMk5b96" "7fJJK56U9fHixgO0HQkhtI" "15Njx2PcwnNsI65fnbM7Pw" "5cqwoGrjFr3VKYZ9ZC0eL2" ...
$ available_markets : chr [1:347] "AD, AE, AL, AR, AT, AU, BA, BE, BG, BH, BO, BR, BY, CA, CH, CL, CO, CR, CY, CZ, DE, DK, DO, DZ, EC, EE, EG, ES,"| __truncated__ "AD, AE, AR, AU, BE, BG, BH, BO, BR, CA, CL, CO, CR, CY, CZ, DK, DO, DZ, EC, EE, EG, ES, FI, FR, GB, GR, GT, HK,"| __truncated__ "AD, AE, AR, AT, AU, BE, BG, BH, BO, BR, CA, CH, CL, CO, CR, CY, CZ, DE, DK, DO, DZ, EC, EE, EG, ES, FI, FR, GB,"| __truncated__ "AD, AE, AR, AT, AU, BE, BG, BH, BO, BR, CA, CH, CL, CO, CR, CY, CZ, DE, DK, DO, DZ, EC, EE, EG, ES, FI, FR, GB,"| __truncated__ ...
$ n_available_markets : num [1:347] 92 76 79 79 87 79 3 79 92 92 ...
$ releaseDate : Date[1:347], format: "2020-08-13" "2020-03-27" ...
$ releaseDate_precision: chr [1:347] "day" "day" "day" "day" ...
$ danceability : num [1:347] 0.5 0.73 0.73 0.701 0.84 0.795 0.814 0.774 0.641 0.571 ...
$ energy : num [1:347] 0.743 0.729 0.777 0.714 0.648 0.607 0.794 0.805 0.324 0.693 ...
$ key : num [1:347] 2 4 1 10 10 7 7 11 11 6 ...
$ loudness : num [1:347] -6.65 -3.43 -6.38 -5.91 -5.54 ...
$ mode : num [1:347] 1 0 0 1 0 1 1 0 1 0 ...
$ speechiness : num [1:347] 0.0373 0.0886 0.29 0.524 0.0489 0.23 0.0887 0.302 0.0299 0.0545 ...
$ acousticness : num [1:347] 0.307 0.167 0.0455 0.289 0.101 0.128 0.119 0.0509 0.698 0.0054 ...
$ instrumentalness : num [1:347] 0.00 1.39e-06 1.10e-03 0.00 1.00e-04 1.90e-01 9.00e-04 0.00 0.00 0.00 ...
$ liveness : num [1:347] 0.133 0.349 0.0759 0.0883 0.0996 0.111 0.348 0.149 0.328 0.173 ...
$ valence : num [1:347] 0.332 0.467 0.578 0.604 0.431 0.25 0.647 0.261 0.273 0.393 ...
$ tempo : num [1:347] 166.3 113 177.9 86.9 103 ...
$ duration_ms : num [1:347] 191827 221820 130307 173353 124690 ...
$ time_signature : num [1:347] 4 4 4 4 4 4 4 4 4 4 ...Merging data II
- The name of the join determines which “ids” are kept
-
left_joinkeeps all rows that have an id in the left dataset -
inner_joinonly keeps rows with ids in both datasets
data1 <- data.frame(group = c('a', 'a', 'b','c'), value = c(1,2,3,4)) # missing group 'd'
data2 <- data.frame(group2 = c('a', 'c', 'd'), value2 = factor(c("abc", "def", "ghi"))) # missing group 'b'
left_join(data1, data2, by = c("group" = "group2")) group value value2
1 a 1 abc
2 a 2 abc
3 b 3 <NA>
4 c 4 def group value value2
1 a 1 abc
2 a 2 abc
3 c 4 def
4 d NA ghi group value value2
1 a 1 abc
2 a 2 abc
3 c 4 defSpecial joins
-
full_joinreturns all rows from both datasets -
semi_joinreturns only the columns of the left dataset and filters rows with id in the right dataset -
anti_joinkeeps only rows that do not have an id in the right table
group value value2
1 a 1 abc
2 a 2 abc
3 b 3 <NA>
4 c 4 def
5 d NA ghi group value
1 a 1
2 a 2
3 c 4 group value
1 a 1
2 a 2
3 c 4 group value
1 b 3Exercise
References
Links
Bibliography
Horst, Allison Marie, Alison Presmanes Hill, and Kristen B Gorman. 2020. Palmerpenguins: Palmer Archipelago (Antarctica) Penguin Data. https://doi.org/10.5281/zenodo.3960218.